Architecting VM-based Applications for Cost Efficiency
Summary: A majority of an application’s lifecycle cost structure is potentially determined during the architecture and design phase, emphasizing the need for proactive involvement rather than post-deployment usage optimization. FinOps practitioners should guide architects and engineers to align VM design decisions with the application’s actual usage pattern, such as designing to scale down resources during light usage periods to maximize the flexibility offered by cloud consumption models. Ask critical questions early about transactional independence, resource mix, and expected peak usage to ensure the final architecture minimizes long-term operational costs.
Introduction
FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value from the cloud. As a result, FinOps practitioners often work alongside engineering, finance, technology and business teams for deployed products and services to reduce and optimize cloud costs.
However, FinOps involvement at earlier stages of the development lifecycle can shift FinOps practices to be implemented in a more proactive manner. Integrating the optimum pricing and usage strategy during the design phase of an application helps to better estimate and optimize costs upfront rather than after deployment. Cost savings realized from such activities can be used for other investments.
Purpose of this guide
The purpose of this paper is to help individuals accurately define requirements by type of application and provide the right information about the product to make effective, responsible cost related architecture decisions. This guidance is meant to be used in conjunction with other best-practice design considerations, such as designing for sustainability, security, etc.
This paper assumes that a decision has been made to build (versus buy) an application and deploy it on a cloud-based infrastructure. Subsequent sprint outputs from this workgroup could delve into issues of make/buy and self hosting versus Software-as-a-Service (SaaS) deployment.
In addition, this paper is focused on the traditional implementation approach of “fleet of VMs”. Other approaches, including containers, and serverless, could be the topic of future papers. A paper is contemplated to discuss the choice of one of these approaches and the pluses/minuses of each.
Importance of Architecting for Cost Efficiency
Cloud computing enables organizations to accelerate innovation, reduce costs, and increase efficiency. But a move to the cloud is no guarantee of business value.
Returns on cloud investments depend on many factors, including innovative leadership and a willingness to make cultural changes. A 2022 Deloitte survey of 500 senior cloud decision-makers in the US found that one of the largest innovation gaps is in organizations’ top strategic priority, reducing/optimizing costs.
Organizations frequently encounter significant gaps to their expected cost efficiency. Simply “lifting and shifting” virtual machines (VMs), storage, networking, and so on into the public cloud may cost organizations about five times what they were spending previously.
Addressing costs during the architecture phase enables cloud architects, engineers, developers, finance, and procurement teams to make informed decisions about VM instance types, load balancing, auto scaling, storage, networking, and purchase mechanisms to meet the application’s business requirements. Using this information, FinOps practitioners can project upfront and annual operating costs for the application. If costs are not addressed during the architecture phase, organizations may face painful choices after the application is deployed. For example:
- After failed attempts to optimize storage spending for petabytes of data, a web software company spent tens of thousands of dollars to vacate the cloud.
- A global company in the healthcare industry discovered they were spending 2x their budget for cloud data analytics.
- Poor visibility into high cloud infrastructure spending caused a customer data platform (CDP) company to see gross margins 20% below industry peers.
- After struggling with capacity forecasting, an e-commerce company announced plans to move some of its operations back on-premises.
- An innovation team that used cloud for the first time to build and test out an idea forgot to switch-off and tear-down their cloud environment after the completion of a PoC, paying $250K per month in unnecessary bills for 6 months.
- A global branded food company had an employee run up a $70,000 bill by running a query all day on a cloud-native data analytics platform. They eventually were able to convince cloud service provider to forgive the expense.
Architecting for cost-efficiency is a consideration, irrespective of the infrastructure deployment model you opt for – whether it’s virtual machines, containers, serverless or even cloud-provider’s managed services. In this document, we focus on virtual machines only, and how you would think and go about designing a virtual-machine-based application for cost efficiency.
It is well documented that in the hardware or physical product world, some 70% of the life cycle cost structure (including initial design, production, operation, and support) is defined at design time, as depicted by the typical chart below. The 70% figure is a general estimate and could vary significantly based on many factors that come into play on each specific project.
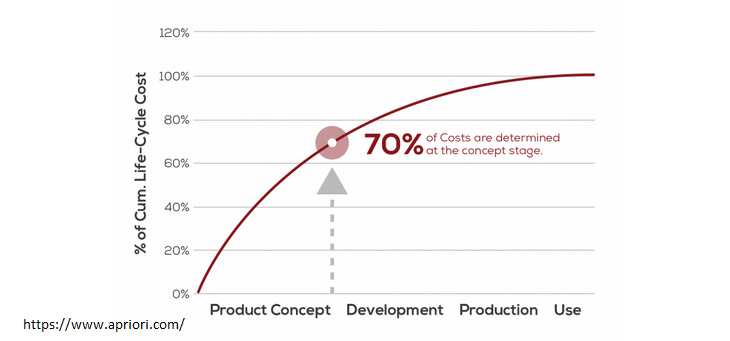
Image courtesy of Apriori.com.
This is not saying that the bulk of the costs are incurred at design time, only that the design dictates the costs that will be incurred later in the life cycle and that design decisions will impact and possibly constrain the choices that one has later in the life cycle as hardware products are produced or supported.
In the cloud/software world, design decisions about the application pattern (client server vs peer to peer vs event bus etc), implementation approach (fleet of VM vs container vs serverless) and degree to which scalability is supported has similar significant impact on ultimate operating cost of the resulting application. Cost can be one of many considerations that impact the design of applications destined for deployment in the cloud.
Many applications have very long useful lives. Architectural and other design decisions made early in the process frequently drive the success of the resulting application along many dimensions. These decisions will define the degrees of freedom that DevOps teams will have in the future to best utilize the then current technology to optimize functionality, non-functional capabilities, and costs.
Virtual Machine Basics
Upfront and ongoing cost considerations
When architecting for VMs, one should consider the cost of the investment and how those costs might change over time. Consider, as an example, electric vehicles (EVs) to explain this. We all know EVs are technologically superior, are more cost efficient, provide a low carbon footprint with reduced emissions and require less maintenance. However, while running costs with EV’s are significantly less, the upfront cost to purchase an EV can be quite high, compared to a traditional non-electric vehicle.
Similarly, though the initial cost of deploying cloud native applications can be somewhat steep in terms of non-recurring engineering and the schedule, the resulting long term operating cost of an application is likely to be low, thereby providing an attractive return on the initial effort and schedule investment.
Virtual machine infrastructure layer considerations
There are multiple considerations with a virtual machine from an infrastructure perspective that teams should be aware of, before designing for a specific business or application requirement. One should start thinking about these aspects from the very beginning, so that business functionality and expectations can be mapped to actual technical requirements.
Some examples are compute (e.g. cores), storage (e.g. object storage), networking (e.g. IO-intensive), etc. See appendix for more information.
Virtual machine application layer considerations
In the world of cloud deployment, since every resource used costs for every moment of use, the incentive is to minimize resource utilization at every opportunity. In many situations, usage patterns vary widely by time of day, day of week, season, external events etc. Thus the very granular flexibility of resource deployment enables one to very accurately match the quantity of resources deployed to the actual usage load experienced (or realistically anticipated) at any point in time. The key is to design applications to be able to take advantage of the flexibility of resource availability that the cloud computing model and cloud vendors offer. The architecture of the application should be able to scale down to a minimum of resource usage during slow periods and take advantage of many resources ( many CPUs, memory, I/O bandwidth, network bandwidth, etc) during periods of high usage.
Requirements for functionality, performance, reliability, and security remain regardless of the implementation approach. While in many organizations the preference is to continue using tried and true approaches and vendors, using these techniques may turn out to be more costly than utilizing alternative approaches. For example:
- Databases can be implemented utilizing traditional proprietary software such as Oracle or MS SQL server or they can be implemented using open source software such as MySQL (MariaDB with support) or PostgreSQL. Databases can be deployed using traditional VMs or using database services such as RDS, Azure SQL or GCP Cloud SQL.
- File systems can be implemented using traditional NFS approaches or other more cloud focused approaches such as cloud block storage or other cloud service provider (CSP) specific offerings.
The remainder of this document highlights factors that one might consider when making critical design decisions and then highlights some of the design decisions that might be made and notes the Persona’s of those making the decisions.
Inputs for architectural decision making
When designing an application for deployment “in the cloud” presumably to run on one of the major cloud service providers, one should consider many factors. A designer gathers and utilizes data when deciding various elements of the design as noted below. These factors impact on many aspects of the design, not only cost.
It is expected that cost is one of many design goals that the design team will attempt to optimize. These apply for totally new (greenfield) design projects as well as projects moving an application from an on-premises implementation to the cloud or redesign/refactoring of an existing application. The categories of inputs include, the following which are described in more detail below:
- Application requirements (including Cloud deployment and operations costs related to DevOps)
- Organizational factors
- Cloud service provider (CSP) capabilities
- Underlying software or framework cloud capability and constraints
Application Requirements
When designing an application for deployment in the public cloud, one should consider many factors. Some of the key factors to consider when thinking about designing for cost include:
Application usage history, trends, and baselines: Data-driven decisions based on peak and average usage help designers develop autoscaled applications based on memory, CPU, number of users, or connections.
Absolute size: Only applications sufficiently large justify the time and expense to optimize for cost in the cloud. One can measure size in terms of number of VMs, users, database size, or current spending.
Resource use mix: One should understand the mix of resources anticipated to be used, to ensure that the right optimizations are considered. Focus, say, on CPU optimizations for CPU-intensive applications or storage optimizations on storage-intensive applications.
Time to market requirement: If this is the overarching business driver, cost may not matter or may not matter for the initial implementation.
Usage pattern: To the extent that there are short periods of peak usage and extended periods of very light usage it might be possible to design an application to take advantage of infrastructure that varies with the usage. For example, one might deploy a base set of a few small instances and add many additional instances during periods of peak usage. A month consists of approximately 720 hours (30×24). An application which is only busy, say, 4 hours per business day (80 hours/month) can utilize a “less resource intensive” configuration 640 hours (720-80) and only require a full configuration 11% of the time.
Functional requirements: The traditional set of business requirements related to what the application is intended to accomplish and drive all aspects of an application architecture.
Transactional independence: It is suggested that teams gather information to characterize their application documenting how each transaction or unit of work depends upon or interacts with other units of work. One of the obstacles to effectively parallel-izing applications so that multiple CPUs or instances can work together is the level of dependency one unit of work has on another. Applications with very high transactional independence lend themselves very well to scaling, and thus only deploying resources as needed.
For example, in a banking system, processing an online payment for one account is entirely independent of processing another account. However, certain simulations might be much more dependent if each iteration is highly dependent on the results of the previous iteration.
Non-Functional requirements: This takes reliability, HA/DR, performance, growth and scalability expected, etc. into consideration.
Rollout Requirements: When designing an application, it’s important to not overlook the processing required when the feature is first rolled out or when new customers are onboarded. For instance, how much/is historical data required on rollout?
Organizational Factors
Frequently, the organizational setting and situation sets forth design goals and constraints beyond the requirements set forth by the application business team. Sometimes these goals and constraints are not explicit and at times can be contradictory. A savvy design team with experience in the organization will understand these types of issues and will shape the architectural design with these types of considerations in mind. These types of things include:
Initiative type and goal: Some development projects exist solely or primarily to address the business need at hand. Some initiatives are supported as a way to spearhead the organization in a new direction. One should understand the organizational goals with each particular application initiative. For example, a given application development activity might be seen as an opportunity to develop new skills and capabilities, even if it is costly to develop in the short term. Management might make a decision to explore a new technology. Or conversely there might be a decision to continue past practice because of concerns about support of a new approach in the operational phase. It is important for the design team to communicate with the business team and management team to ensure consistent, clear expectations and to highlight tradeoffs in many areas, including cost.
Skills/experience with various technologies: Technology organizations typically have “comfort zones” where they are comfortable designing and supporting applications. These comfort zones are informed by skills of the team members as well as experience of management. One might have an approach for a cost optimized design that is outside of the organizational comfort zone.
Preferred design patterns: Some typical patterns are set forth in the Appendix. There are operational cost implications of the various patterns; applications can be implemented using more than one pattern. The application team should consider which of these patterns is most suitable to optimize all the project goals, including functional, non-functional, goals, and cost optimization. To the extent that the proposed pattern is different from the organizational comfort zone, this should be highlighted to many personas to gain agreement to proceed with such an approach. Some of these patterns appear to be more amenable to scaling and thus better approaches to implement applications with highly variable usage patterns.
Design processes. Need any proposed approach to fit with current organization practices (although in the long term there might be an opportunity to change such processes).
Benchmarks: Initiative type and where the current application is positioned relative to overall organizational strategy.
DevOps process maturity: The term “FinOps” typically refers to the emerging professional movement that advocates a collaborative working relationship between DevOps and finance, resulting in an iterative, data-driven management of infrastructure spending (i.e., lowering the unit economics of cloud) while simultaneously increasing the cost efficiency and, ultimately, the profitability of the cloud environment. Therefore, DevOps maturity is an important factor in controlling cost through automation and measurement of everything, to include costs.
Application and automation maturity: FinOps collaborated closely with application, database, and infrastructure teams to reduce the overall Total Cost of Ownership (TCO). As a result, a robust understanding of application architecture and automation plays a critical role in optimizing cloud usage, reducing TCO, and enhancing the user experience.
Policies: There might be a policy to avoid some approaches or to utilize some approaches, increasing the need to adhere to policies in the short term, with the opportunity to consider changing such over the long term. Designers need to work with business and product leaders to flesh out what these might be and how it would impact design for cost considerations.
Cloud service provider (CSP) considerations
As teams make application architecture choices, they should consider CSP capabilities that may have a significant effect on the costs to deploy and operate the application. Consider the following:
Details about instances capabilities and prices: This capability identifies inconsistencies that might sway the selection of one instance type vs another (say, implied price for incremental memory on one instance family is lower than another and given that the application needs more memory). The key here is to do a financial review as well as a technical review when selecting instances. Cloud-native and third-party monitoring and observability tools can help compare cost efficiency of various options. For example, ARM-based instance types may cost significantly less for a given application.
Details about instance scaling capabilities: If an application has a load that is highly variable by time of day, day of week or season (e.g., open enrollment for health insurance) and there is an opportunity to realize savings by varying the resource use by time, one needs to understand in detail the scaling capabilities (e.g. autoscaling) of the CSP as well as the application.
Details about capacity management: Although cloud resources may seem endless, unfortunately, they are not. It is critical to be aware that each cloud provider does have a limited amount of infrastructure to support each resource and service. This may not be something you run into when using higher use services/instance families/regions (e.g., it is unlikely you will run into capacity issues if using a t3 family EC2 instance in us-east1). However, for more specialized instance types or services in lesser used regions, you may run into capacity issues. Or even worse, the instance family/service may be completely unavailable in that region.
Details about pricing of instances and relative cost of CPU, memory, and additional IO capability: Tradeoffs can be made by adding additional memory to cache data vs additional IO speed. Understanding this pricing will inform whether one wants to undertake the effort to implement horizontal (additional instances) or vertical scaling (reconfiguring instances to include a different amount of vCPUs or Memory), and the absolute and relative cost effectiveness of each approach.
Details about the differences between the various storage subsystems: This may include technical issues such as compatibility with other hardware and software being deployed, storage capacity, access speed including latency and I/O bandwidth (IOPS), reliability, fault tolerance/disaster tolerance, and cost issues.
- For example, AWS offers object storage, block storage and file system storage. One should be clear which type of storage is required for the contemplated use case based on technical requirements as well as cost.
- Availability of storage tiering where the CSP automatically migrates infrequently used data stored in “expensive, fast” subsystems to slower lower cost subsystems. Some CSPs might enable applications to do this sort of migration with application specific knowledge of the data to make better decisions about what should be stored where.
- For example, AWS offers EFS and FSx for windows file systems. FSx appears to be lower cost; one should understand other technical considerations when making that choice.
Design/architecture strategies to apply to your process
During the design process, having a strategic definition with a lens of a “bird’s eye view” is helpful. This could be a statement like, “The product must be able to scale fast and be able to withstand compute interruptions.” Strategic statements like this outline the business requirement and approach.
The strategic definition provides guidance to the technical and FinOps teams to work on more in-depth (a.k.a Tactical) design that will provide the desired effect: use smaller instances, define scaling policies, deploy Spot instances etc. The combination of the two is crucial for a successful implementation of designing with FinOps in mind.
Strategic decisions refer to big conceptual decisions typically made at the outset of a project. One characteristic of strategic decisions is that they are not easily changed once made and design work commences. A decision to use a fleet of VMs vs a serverless approach is such a strategic decision (although out of scope for consideration in this document). These decisions could include which design pattern or approach such as client/server vs pipeline to use.
Vertical vs horizontal scaling
With VMs in the cloud, one can use vertical (rightsizing) or horizontal (auto scaling) scaling strategies. These can be scaled either automatically (e.g., using CPU) or on a schedule (e.g., runs at 5pm). Vertical scaling and horizontal scaling are two different approaches to scaling resources in the cloud. Vertical scaling involves increasing the capacity of a single/group of servers or instances, while horizontal scaling involves adding more servers or instances to distribute the workload (see Appendix).
The decision between vertical and horizontal scaling depends on factors such as cost, performance, maintenance, and application architecture. Vertical scaling can provide better performance for resource-intensive applications but can be more expensive and result in single points of failure. Horizontal scaling can provide better fault tolerance and high availability but can increase overall costs. The application architecture can also play a role, with microservices or containerized applications benefiting more from horizontal scaling, and monolithic applications requiring more vertical scaling.
Elasticity is a key benefit of the cloud, and companies often take advantage of this to scale their systems on demand. This ability comes at a price though, and cloud vendors charge more for on-demand resources.
If workloads are stable, one can think about committing to using resources over a period of time to get more favorable prices. Resource commitment plans (Savings Plans or Reserved Instances for AWS) refer to customers committing to a relatively long commitment of 1 or 3 years, possibly with an upfront payment, for a reduced on-going price. Design teams need to be cognizant that long term commitments to vendors are typically 24×7 commitments for the particular resource or a spending level. An alternative is to design the application to support time varying resource utilization such that resources are not needed 24×7 and can be scaled up in response to usage load.
To the extent that one can design an environment which dynamically scales to respond to usage demand, one strategy might be to make the long term commitment for the minimum amount of resources that keep the application “alive” and not make a long term commitment for incremental resources that are only required during relatively short peak busy times, say prime business hours, or in response to an external event like an advertisement running on TV encouraging viewers to visit a website.
Applications with the following non-functional characteristics tend to be good candidates for dynamic scalability:
- Variable usage patterns
- Fault Tolerant
- Highly Available
Technically, applications that can take best advantage of the scalability capabilities need to exhibit these functional characteristics
- Transaction or work element independence
- Have the capability to make calls to the CSP scaling API to implement the resource scaling, or expose the required performance metrics so an external application can use the data to make scaling decisions and call the CSP APIs
- Be designed in such a way that the work/computing tasks can be decomposed into tasks that can be performed in parallel
Procurement strategies for virtual machine instances on the cloud
One way to design for costs could be to leverage commitment and reservation-based discounts for virtual machines (Savings Plans, Reserved Instances etc.). By signing up to reserving and committing to using a fleet of virtual machines for 1 or 3 years (with no or partial upfront payments), you can save 30-70% of on-demand costs.
Licensing strategies with virtual machine instances on the cloud
It is important to understand the licensing and compliance side of cloud ahead of migration application(s) to cloud. (i) Unlike ‘On Prem’ Operating System (OS) licensing, cloud licensing could get heavily complex. (ii) require additional OS licensing understanding which in many cases is not only subject to frequent possible changes but also this is CSP dependent (iii) Intentional / unintentional non-compliance could attract legal fines and penalties of hundreds of thousands of dollars. As we know each CSP wants to promote their own cloud services (and hence in turn) enforces and erects heavy fencing.
For example, Microsoft Office licensing for Office / SharePoint for Azure is relatively lenient / accommodative compared to AWS and other CSPs. One needs to be mindful of such additional licensing costs (including Enterprise Agreement (EA) / Software Assurance (SA) and license mobility rules.
Tactical decisions
Instance types
When selecting instance types for the cloud, there are several tactical considerations that companies should take into account to ensure optimal performance, scalability, and cost-effectiveness. Here are some key considerations:
- Workload: Determine the type of workload that your application will be running and select an instance type that is optimized for that workload. For example, compute-intensive workloads may require high-CPU instances, while memory-intensive workloads may require high-memory instances.
- Scaling: Consider the scalability requirements of your application and select an instance type that can easily scale up or down based on demand. This will help you optimize resource utilization and reduce costs.
- Network performance: Consider the network performance requirements of your application and select an instance type that provides high network throughput and low latency. This is particularly important for applications that rely heavily on network communication.
- Storage: Consider the storage requirements of your application and select an instance type that provides the appropriate amount of storage capacity and performance. This includes selecting an instance type with the appropriate type of storage (e.g., SSD vs. HDD) and IOPS performance.
- Operating system: Consider the operating system requirements of your application and select an instance type that supports your operating system of choice. This includes selecting an instance type with the appropriate CPU architecture (e.g., x86 vs. ARM) if necessary.
- Tenancy: instance tenancy refers to the way in which virtual instances of computing resources are isolated and dedicated to a specific user or group of users (e.g. shared tenancy vs dedicated instances).
Spot instances
Spot instances are ideal for applications that have flexible processing requirements and can tolerate interruptions. Examples of application types that are suitable for spot instances are batch processing, testing and development environments, image rendering, high-performance computing and web applications servers with variable traffic.
Infrastructure automation tools such as cloud formation templates, Terraform, or container orchestration tools like Kubernetes can help simplify the process of designing, deploying, and managing fault-tolerant architectures on spot instances. These tools can help reduce the cost and effort required to manage spot instances.
In general, applications that are designed to be fault-tolerant, scalable, and resilient to interruptions are more suitable for spot instances. Here are some examples of application types that may not be suitable for spot instances: time-critical applications, mission-critical applications, long-running applications, and applications with high input/output (I/O) requirements.
Storage types
There are two main types of storage options available in the cloud that can be used alongside VM-based applications. VM-based applications often also use Object storage, Archive Storage and Backup Storage services in CSPs.
- Block storage: Block storage is designed for structured data such as databases and file systems. Block storage is typically accessed through standard block-level protocols such as iSCSI.
- File storage: File storage is a storage option that provides a shared file system that can be accessed by multiple virtual machines. File storage is designed for structured data such as user home directories, application data, and configuration files. File storage is typically accessed through standard file-level protocols such as NFS or SMB.
Provisioned IOPS (input/output operations per second) is a type of block storage option available in the cloud that allows you to provision a specific level of IOPS for your storage volume. This is useful for applications that require consistent and predictable performance, such as high-performance databases.
Provisioned IOPS can be scaled up or down to match changing requirements. This allows you to adjust IOPS to match changes in application workload. Provisioned IOPS can be more expensive than other block storage options, such as standard SSD or HDD volumes.
Networking enhancements
Dedicated network adapters for cloud VMs, also known as enhanced network adapters, are hardware devices that provide higher network performance than standard network adapters. These adapters are specifically designed for cloud workloads and can provide higher throughput, lower latency, and better packet processing performance.
Dedicated network adapters are available on some cloud platforms, such as Amazon Web Services (AWS) and Microsoft Azure. For example, AWS offers the Elastic Network Adapter (ENA) for EC2 instances, which provides up to 100 Gbps of network throughput and reduced latency compared to standard network adapters. Similarly, Microsoft Azure offers the Accelerated Networking feature for virtual machines, which provides up to 30 Gbps of network throughput and low latency.
The dedicated network adapters are designed to reduce the overhead of network processing on the VM’s CPU, which improves application performance and reduces CPU utilization. They use specialized hardware, such as network processing units (NPUs), to offload network processing tasks from the CPU, such as packet processing, checksum calculation, and interrupt handling.
Process considerations
Whilst making architectural decisions, it is important to estimate the cloud costs of those decisions to avoid surprisingly expensive choices. For example, when selecting the instance types, storage types or IOPS and networking enhancements, calculate the cost of your choices before the system is deployed. Estimates can also be revised and made more accurate as more is known during the system development cycle.
Depending on your FinOps maturity, you might consider:
- Crawl maturity phase: Using spreadsheets to estimate costs. A challenge with this manual approach is that it can be time intensive as there are more than 3.5 million prices between CSPs and the prices used in your spreadsheets can become out of date.
- Walk maturity phase: Using CSP cost calculators to estimate costs. These calculators solve the out-of-date price issue but they are difficult to use at scale and aren’t part of people’s existing workflows/tools. You can also consider setting budget alerts based on these estimates.
- Run maturity phase: Using automated tools to estimate costs. These are quicker to use at scale in the engineering workflow (e.g. VS Code code editor, or GitHub pull requests) and non-engineering workflow (e.g. Jira). You can also consider setting budget notifications based on estimates and tracking actuals against them.
Persona Involvement
Creating a cost-efficient cloud application requires innovative leadership and collaboration among highly skilled teams. Business requirements inform each of the crucial architectural and design decisions. In the requirements phase, product, finance, procurement, and FinOps teams collaborate to define inputs to measure the application’s effectiveness such as critical user journeys, user experience metrics, and service level agreements (SLAs).
Once business requirements are well understood additional teams help define the application architecture. Developers, designers, cloud architects, functional architects, cloud engineers / Ops, and DataOps evaluate the set of potential options that will most efficiently and cost-effectively address the business requirements. Below is a sample product development timeline showing the people involved at each stage. Smaller organizations may combine these roles/responsibilities.
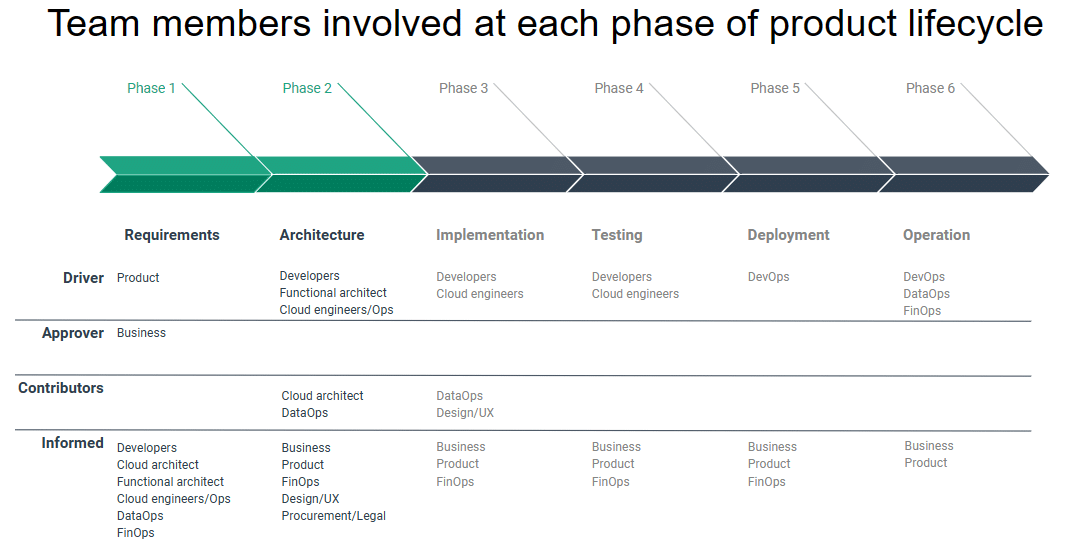
FinOps involvement should start in the requirements phase, when product and business teams start to formulate the concept of the new product, use cases, and features. Discussions during the architecture phase enables FinOps practitioners to more accurately estimate total cloud costs, identify the primary cost drivers, and recommend the best strategies to maximize profitability.
Requirements phase roles and deliverables
| Team or role | Inputs to FinOps practitioner | FinOps deliverables |
| Product | Application vision, use cases, goals, business metrics, SLAs, and expected usage patterns | Cost allocation plan and examples of success |
| Finance | Overall application budget, revenue, profitability goals | Estimated annual product revenue and expenses |
| Business leader | Approves business application requirements, budget, revenue, and profitability goals | Estimated annual cloud application costs, cost drivers and break-even analysis |
| Procurement/Legal | Preferred cloud and software vendor selection criteria, spend commitments, consumption discounts, data sovereignty and regulatory requirements | Estimated annual cloud application costs |
| Cloud architect | Viability, cloud considerations | Estimated annual cloud application costs, allocation plan |
Architecture phase roles and deliverables
</tableForecasting cloud costsBefore completing a design, cloud architect, engineers, and procurement team collaborate to forecast cloud application costs. Leverage well architected frameworks to maximize cost efficiency (AWS, Azure, Google Cloud, Oracle Cloud). Depending on the organization and how rate optimization is managed, this may require a number of steps. The following questions should be considered:
- Does the expected usage profile warrant rate optimization vs. on-demand flexibility?
- How would rate optimization affect application cost?
- Does the organization manage rate optimization centrally?
- Will the initial deployment or future upgrades require additional processing?
- Does the forecast account for application usage growth?
ConclusionThis document highlights that making strategic and tactical design/architecture decisions have a huge impact on the total cloud application life cycle cost including development, operations, and support. The document focuses on what those decisions are, the factors driving those decisions including application requirements, organizational factors, and capabilities of the chosen CSP. The document then highlights the personas of those making these decisions.Since cloud cost is a function of resources operating and utilized at each moment in time, matching resource commitment on a time varying basis with expected user/usage load, scaling up during busy periods, scaling down during slack periods is one approach to controlling cloud costs.AcknowledgmentsWe’d like to thank the following people for their time and effort in contributing to this Working Group and to this asset.
| Team or role | Inputs to FinOps | FinOps deliverables |
| Product | User personas, expectations, stories, and customer feedback | Cloud application cost drivers and break-even analysis |
| Finance | Application usage growth forecasts and efficiency metrics such as cost per user, per transaction, or per session | Cloud application cost drivers, allocation plan, and efficiency metric estimates and targets |
| Business leader | Approves application development | Estimated application profit margins, efficiency targets |
| Procurement/Legal | Software-as-a-service (SaaS), Commercial off-the-shelf (COTS) recommendations for application, database, observability, and software and when to buy an application rather than build a new application | Estimated usage of committed cloud services, SaaS, and COTS software by time period and season (e.g., per hour, day, week, month, quarter, year) |
| Developer | Reliability, performance, scale, resiliency goals and proof-of-concept test to establish baseline and peak usage costs | Cloud instance pricing, cost benchmarks, considerations, and examples of success |
| Design/UX | Recommended frameworks to support application UX design and estimate cloud server load such as API requests per second, and average request size | Considerations to maximize cost efficiency while minimizing delays during peak usage times. |
| Cloud architect | Cloud design options, recommendations, and considerations | Estimated cost savings with cloud cost efficiency recommendations, cloud cost management considerations |
| Functional architect | Hardware, software, compute, storage, and networking for functional requirements, regulatory compliance, and cost efficiency | Potential cost savings with cloud cost efficiency recommendations and examples of success |
| Cloud engineer / Ops | Reliability, performance, scale, resiliency requirements and observability plan to optimize application cost efficiency | Cloud application cost drivers, efficiency metric estimates, cost benchmarks, considerations, and examples of success |
| DataOps | Data observability plan to optimize cost efficiency for data pipelines and analytics | Data cost drivers, efficiency metric estimates, data cost benchmarks, considerations, and examples of success |

Ali Khajeh-Hosseini
Infracost
Amit Doshi
PSEG
Assaf Flatto
2bcloud
Clinton Ford
Unravel Data
Eric Hilman
Commonwealth of Massachusetts
James Gambit
Bank of America
Jay Mohapatra
Alix Partners
Jesse Albright
Deloitte
Dr. Maneesha Asundi
Mr. Cooper
Nour Shurbaji
VMWare
Sangeetha Bhosale
KPMG
Stephen Davis
Bridgestone Americas
Lucas Paratore
CloudHealthAppendices
Appendix 1: Virtual machine infrastructure layer considerations
Compute
Does my application require dedicated or reserved capacity from the underlying physical computer? Do I need to reserve all CPU cores for my virtual machine at all times? E.g., exactly 4 cores or between 2-4 cores? Do I need CPU hyperthreading enabled or disabled? What type of processors can I consider – Intel / AMD / Graviton?
Storage
Does my application require high-performance storage? Do all my application components require high-performance storage, or can I break them down, for example, to high-performance storage for the database only, and standard storage for everything else? For object storage requirements, do I need all my data to be equally responsive to access requests at all times, or can I move data older than x days to a low-tier storage?
Networking
Does my application require IO-intensive network throughput? Do I require multiple network interfaces either for resiliency or for performance? Is the packet size flowing through my network interface of standard size or larger size (bursts, remember MTU?)
Operating System
Is my application tied to a specific operating system or version? Or do I have flexibility between, for example, a completely open-source free OS vs a premium enterprise OS?
Operational requirements
Does my application require a lot of manual tinkering to provision, scale and retire? Or can I leverage automation from the outset, to perform 10-15-50% of operational tasks?
Appendix 2: When to use a virtual machine (vis-a-vis physical, containers or serverless)?
| Deployment Model | Key Features | Key Compromises | Best Suited for |
| Bare-metal (physical) |
|
|
|
| Virtual Machine |
|
|
|
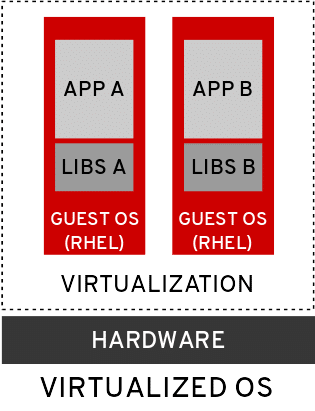
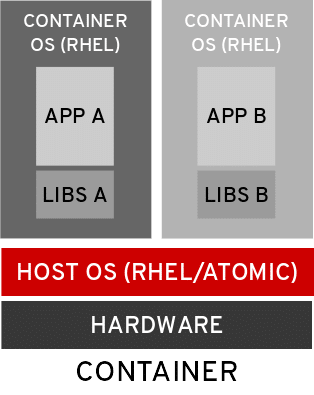
| Container: Typically refers to an infrastructure construct, where the application, its dependent libraries and the OS are packaged together to form a single deployable unit of infrastructure, making a container independent and ultra-portable.
Applications can be container-based, but don’t necessarily have to microservices-based*. |
|
|
|
| Serverless: Typically refers to a model where infrastructure gets deployed only upon invocation, either via an event or a trigger, and the infrastructure gets torn-down immediately after the task is completed. For example, the infrastructure required for order fulfillment gets deployed via serverless only after a user saves an order in the basket. Until then, there is no underlying infrastructure that is running and waiting. As you see, this is typically applicable to event-driven applications, focused on specific tasks. This is particularly attractive when your application has to scale up and down based on demand, as you pay for infrastructure only if there is a demand. |
|
|
|
Appendix 3: Microservices
Micro-services typically refers to an architecture construct as a way to separate multiple functionalities and layers of a large application into their own decoupled and independent tiny services.
Take an e-commerce application for example, with individual micro-services for:
- The shopping portal
- Add-items-to-cart
- Check-out
- Payment processing
- Order notification
Each micro-service is independent, so we could switch-out the database for “Add-items-to-cart” micro-service from MYSQL to PostgreSQL, without impacting any other micro-service.
Micro-services are typically containers-based, but can also be architected using serverless.
Because micro-services are typically not implemented on VMs, they have not been fully detailed in this deliverable. The Working Group may explore cost efficiency strategies for container and serverless architectures in future sprints.
 |
 |
Source: Red Hat
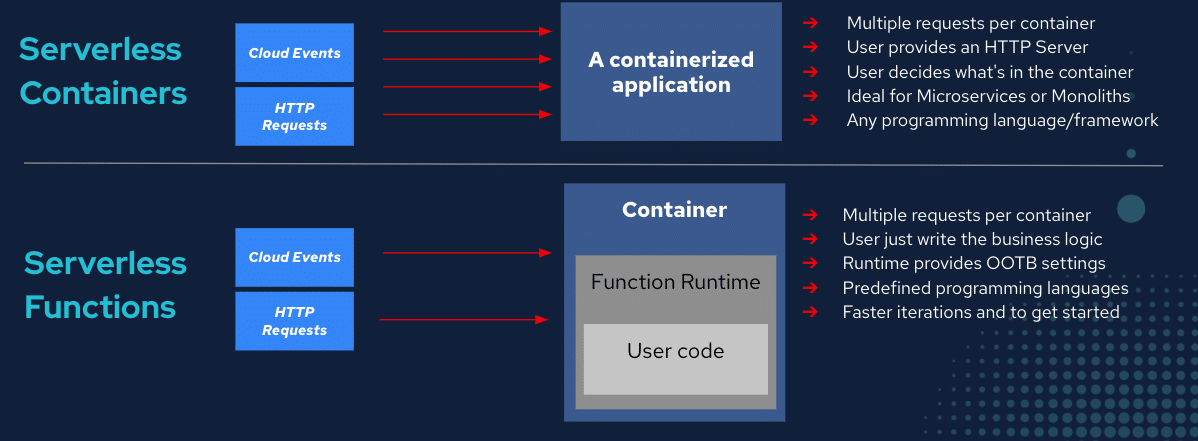 Source: ContainerJournal.com
Source: ContainerJournal.com
Appendix 4: Directional Scaling
| Scale-up – Vertical scalingAlso referred to as vertical scaling, usually refers to a scenario where you would add more resources to the same virtual machine so that it can serve the increased resource requirements of the application.
For example, a VM with 2 CPU’s, 4GB memory and 50GB storage gets scaled up to 4 CPU’s, 16GB memory and 100G storage One thing that you should have in mind is that during expansion there is a likelihood that performance will be affected intermittently or temporarily. Scale-up is a common pattern in legacy/traditional monolithic applications |
Scale-out – Horizontal ScalingAlso referred to as horizontal scaling or up and down scaling. This type of scaling involves adding more virtual machines or servers to enable load distribution across the infrastructure.For example, you scale out from 3 VM’s to 10 VM’s as the application has to serve 100 more users than previously.
This scaling is quite unique from the vertical because in the vertical you only scale a single machine or server. However, horizontally your scaling is multiple machines or servers. One key characteristic of horizontal scaling is that each machine or server needs to be independent in order to be called separately when scaling out. Scale-out is a popular pattern in modern cloud-based applications. It is important to note, not all applications support horizontal scale-out |
Diagonal Scaling: This is not your usual scaling type because it involves the combination of vertical and horizontal scaling. This scaling normally happens when the vertical scaling limit is reached, then the company begins adding more machines or servers as needed to ensure there is no cut-off in delivery. |
For both vertical or horizontal scaling strategies, you use the cloud’s elasticity to scale dynamically; often using the following two options:
- Auto-scaling: Implement auto-scaling policies to automatically add or remove instances based on demand. This ensures that you have enough resources to handle traffic spikes without over-provisioning and incurring unnecessary costs during periods of low demand. Autoscaling based on CPU, RAM, network traffic, or queue size are common metrics used to trigger autoscaling actions. It is important to note that all of these strategies require engineering effort to implement and fine-tune. Cloud vendors provide APIs and services that can be used by engineering teams to implement these strategies, but cloud vendors cannot automatically autoscale an application for you. Here’s a brief description of how various metrics can be used for autoscaling:
- CPU-based autoscaling: This approach involves monitoring the CPU utilization of an application or service, and adding or removing instances as needed to maintain a target CPU utilization level. For example, if the CPU utilization of an application exceeds a certain threshold for a specified period, additional instances can be launched to handle the increased load.
- RAM-based autoscaling: This strategy is similar to CPU-based autoscaling, but instead of monitoring CPU utilization, it monitors the amount of available memory. When the available memory falls below a certain threshold, new instances are launched to handle the increased load.
- Network traffic-based autoscaling: This approach involves monitoring incoming and outgoing network traffic to an application or service, and adding or removing instances as needed to maintain a target level of network traffic. For example, if the network traffic exceeds a certain threshold for a specified period, additional instances can be launched to handle the increased load. Load balancer-based autoscaling is a popular strategy for scaling web applications and services. In this strategy, a load balancer is used to distribute incoming traffic across multiple instances of an application or service. As the load on the application increases, additional instances are launched and added to the load balancer pool, and as the load decreases, instances are removed from the pool.
- Queue size-based autoscaling: This strategy involves monitoring the size of application queues, such as message queues, task queues, or job queues, and adding or removing instances as needed to maintain a target queue size. For example, if the queue size exceeds a certain threshold for a specified period, additional instances can be launched to handle the increased workload.
In practice, a combination of these metrics can be used to trigger autoscaling actions. For example, CPU and RAM metrics can be used in conjunction with network traffic or queue size metrics to achieve optimal performance and resource utilization.
- Scheduled scaling: Use scheduled scaling to temporarily increase or decrease resource capacity based on predictable spikes or dips in demand. For example, you can schedule additional resources during peak hours and reduce capacity during off-peak hours to save costs.
As the above options are evaluated, consider the scaling capabilities of the CSP as well as the application, asking questions such as the following:
o What calls are available to the application to activate or deactivate additional instances/VMs
o How long it takes from the time a request to activate an additional instance until the time that the new instance is really available to process application requests. This will inform scheduling approaches
o Can instances be reconfigured “on the fly” to add more vCPUs or more memory? If so, what are constraints? How long does the reconfiguration process take? Can this reconfiguration be implemented via software calls. This will inform the ability to scale vertically vs horizontally. To the extent that an application can make good use of additional resources like vCPUs and memory and it is implemented using many VMs it might be possible to take a VM off line for the time necessary for a reconfiguration operation and then resume, that VM, allowing other VMs to be reconfigured in sequence in anticipation of or in response to an increase in load.
Appendix 5: Application Design pattern references
Paper on Design patterns from Medium: https://towardsdatascience.com/10-common-software-architectural-patterns-in-a-nutshell-a0b47a1e9013
Book/report published by O’Reilly on this topic:
Software Architecture Patterns Understanding Common Architecture Patterns and When to Use Them, by Mark Richards, ISBN: 9781491924242, https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/
Last updated: September 24, 2025