How to Forecast AI Services Costs in Cloud
This paper delivers a summary of the financial and operational complexities involved in implementing various types of Artificial Intelligence (AI) systems. From grasping the key cost drivers and establishing effective guardrails to navigating capacity management, these insights and guidance aim to equip FinOps practitioners with a toolkit of considerations as they use AI/ML (Machine Learning) systems.
Whether you are considering a 3rd-party vendor, an open model platform, or a DIY (do-it-yourself) cloud-based solution, this paper serves as a valuable resource for making informed decisions. It provides insights needed to design for value, forecast with accuracy, and manage capacity effectively, all while balancing performance and cost.
Who Should Read this Paper
This paper is intended for FinOps personas managing the cost and usage of AI systems. It is appropriate for anyone managing or advising on the cost considerations of using or building AI systems. This paper may also be valuable to anyone considering building or using AI systems within an organization, to understand some of the cost considerations that should go into the use of such systems.
NOTE: This paper does not address using AI/ML systems to perform FinOps functions.
Prerequisites
Readers should have the following knowledge to use this paper effectively.
Knowledge Requirements
- Basic Understanding of Artificial Intelligence: Readers should be familiar with the core concepts and terminologies related to AI, such as machine learning, natural language processing, etc.
- FinOps Background: A fundamental understanding of FinOps principles, including cost management and financial planning, is essential
- Cloud Computing Familiarity: Given that the paper focuses on AI deployments in cloud environments, a working knowledge of cloud service providers like AWS, Azure, or GCP is recommended
Target Audience
- FinOps Practitioners: Especially those looking to gain insights into managing costs related to AI implementations
- AI/ML Engineers: Who want to understand the financial implications of deploying AI models and workloads
- Cloud Solution Architects: Interested in optimizing the costs of AI workloads on cloud platforms.
- Business Analysts: Who work closely with FinOps and tech teams to balance costs and performance in AI projects
Scope of the Paper
The landscape of Artificial Intelligence (AI) is vast and quickly-evolving.
This paper provides the findings of FinOps practitioners using AI across sectors and industries and elaborate on techniques to make cost fully visible and quantifiable across the entire AI applications’ lifecycle – like techniques for calculating TCO (Total Cost of Ownership) or estimating AI costs. The working group produced this paper to accelerate adoption and community value for FinOps practitioners managing AI/ML workloads. It will enable Finance and Product Engineering teams to understand AI systems, the resources they use, and their unit costs. This will provide a reference for how cost estimation and shared costs showback of AI services is being done today.
The first sections of this paper describe different types of AI/ML systems, and some of the considerations when selecting or using them. With applications ranging from machine learning and natural language processing to computer vision and robotics, the cost considerations for AI implementations can be exceedingly diverse and complex. In light of this, in later sections this paper narrows its scope to the most widely-adopted categories of AI applications to maintain focus and relevance, the text based large language models.
By centering on this workload type, this paper aims to provide FinOps professionals with actionable insights to forecast AI costs, understand cost drivers, improve efficiency, and provide examples of how other enterprises are managing AI cloud spend to drive successful outcomes.
Certain aspects of AI-related costs will not be covered in this paper:
- Self-Hosted Workloads: The paper will not delve into AI implementations that are self-hosted in a data center, as they have a different set of financial dynamics.
- Data Acquisition Costs: Since data is the foundation of any AI model, its acquisition and management can be a significant cost factor. However, this aspect will be excluded to focus on computing and operational costs of AI tasks.
- Legal, Ethical use, bias, intellectual property and data ownership issues: these are important considerations for AI/ML systems which have costs that are difficult to generalize.
Common types of AI systems being deployed today:
Today the enterprises deploying AI offerings are using 3 deployment options to meet the needs for their requirements across quality, privacy, accuracy, performance and costs. The 3 models are:
- Third-Party Vendors Closed Source Services
- Third-Party Hosted Open Source Services
- DIY on Cloud Providers AI Centric Services/Systems
The various deployment options are used to satisfy different stages and rollout of the AI service from proof-of-concept, training, validation, performance through to full adoption production scale. Being a newer technology, breakthroughs and improvements occur frequently. But below are some of the notable pros and cons of each approach as it stands today.
Third-Party Vendor Commercial Closed Source Service: These are turnkey AI solutions offered by OpenAI, Google, and Microsoft. They are packaged, managed services that require minimal setup and are generally billed on a usage-based model.
- Pros: Quick to implement, high-quality models, and robust customer support.
- Cons: Less customizable, potential for vendor lock-in, bias/privacy risks, and often higher costs due to proprietary technology.
Third-Party Hosted Open Source Models: Platforms like Anyscale, HuggingGPT, Render, Lambda, and Replicate fall under this category. They offer a range of pre-built training and fine tuned models that are customizable to some extent and are usually based on open-source technologies.
- Pros: Greater flexibility/control in customization, privacy/security compliance, community support, and often more cost-effective than closed source services.
- Cons: Quality, accuracy, performance are up to you, requires a higher level of technical expertise, time to results is longer, and less streamlined support channels.
DIY on Cloud Provider AI Centric Services/Systems: For organizations that prefer to build and deploy AI models in-house, cloud providers like AWS Bedrock/Sagemaker, GCP Vertex, and Azure AI offer the infrastructure and tools needed for a DIY approach.
- Pros: Full control over the model, privacy/security compliance, customizable cost management, and integration with other cloud services.
- Cons: Quality, accuracy, performance are up to you, requires significant expertise in both AI and cloud management, and potentially longer time-to-market.
The AI landscape is expanding in terms of provider offerings and the type of AI tasks it can handle. Below is a partial listing of the single mode(one main function like text summarization) vs multimodal (multiple modes at once like image, video, text and audio). This paper is referring to the single modal text summarization use case as a base example for AI cost forecasting and management.
Single Task: Text Summarization Large Language Models
| Task | Proprietary | Open Source |
| Text Summarization | OpenAI – ChatGPT 3.5/4 | |
| Text Summarization | Google – Workspaces Gdocs | |
| Text Summarization | Google – Document AI | |
| Text Summarization | Google – Vertex | |
| Text Summarization | Google – Bard/Gemini | |
| Text Summarization | Google – Palm2 | |
| Text Summarization | Google – Palm2 in Vertex | |
| Text Summarization | Anthropic – Claude | Google – Claude/Anthropic |
| Text Summarization | AWS – Titan | |
| Text Summarization | AWS – Jurassic | |
| Text Summarization | AWS – Bedrock | AWS – Bedrock + OSS Claude/Llama2 |
| Text Summarization | AWS – Textract, Comprehend, Augmented AI | |
| Text Summarization | ||
| Text Summarization | Azure – 0365 Docs | |
| Text Summarization | Azure – OpenAI Service | |
| Text Summarization | Azure – Language Understanding LUIS | |
| Text Summarization | Azure – Document Intelligence | |
| Text Summarization | Box – BoxAI | |
| Text Summarization | Dropbox – Dash | |
| Text Summarization | OSS – Facebook Bart | |
| Text Summarization | OSS – Zephyr | |
| Text Summarization | OSS – Mistral | |
| Text Summarization | OSS – Llama2 | |
| Text Summarization | OSS – Falcon |
Single Task: Text to Code Large Language Models
| Task | Proprietary | Open Source |
| Text to Code | OpenAI- GPT w ADA advanced data analysis/code interpreter | |
| Text to Code | OpenAI – ChatGPT4 w Plugins | |
| Text to Code | Google – Codey | |
| Text to Code | Google – Bard/Gemini | |
| Text to Code | Google – Studio Bot | |
| Text to Code | Google – Maker Suite + Palm API | |
| Text to Code | Google – Vertex AI | |
| Text to Code | Google Deepmind – Alphacode | |
| Text to Code | Azure – OpenAI Service | |
| Text to Code | Microsoft Github Copilot | |
| Text to Code | Tabnine | |
| Text to Code | Divi AI | |
| Text to Code | AWS – Bedrock + Titan | |
| Text to Code | AWS – CodeWhisperer | |
| Text to Code | OSS – CodeLlama | |
| Text to Code | OSS – WizardCoder | |
| Text to Code | OSS – Dolly | |
| Text to Code | OSS – Replit | |
| Text to Code | OSS – Codegen |
Multimodal AI models enable a combination of multiple types of inputs and outputs across text, audio, image, video, data, and sensors.
| Multimodal | Proprietary | Open Source |
| Multimodal | OpenAI ChatGPT-4V | |
| Multimodal | Google – Vertex Multimodal Embeddings & Vector Search | |
| Multimodal | Google – Bard/Gemini | |
| Multimodal | Google – Palm-E | Google Palm-E, PaLi-X |
| Multimodal | Google – Deepmind | |
| Multimodal | AWS – Bedrock, Sagemaker, Titan, Textract, Comprehend, Transcribe, Kendra | |
| Multimodal | Azure – OpenAI ChatGPT-V | |
| Multimodal | Azure – Cognitive Services | |
| Multimodal | OSS – Llava | |
| Multimodal | OSS – Meta ImageBind | |
| Multimodal | OSS – Adept Fuyu |
Key considerations for selecting an AI deployment solution
Modern AI services target specific user stories and have varying levels of requirements to align to the best deployment solution for that need, some of the considerations listed here:
-
- Nature of the Application: Is your software focused on voice recognition, image processing, machine vision, text summarization, data analysis, or code copilot? Each application type demands distinct performance, latency, and specialized models.
- Solution Complexity: Is your project as straightforward as a website chatbot or as intricate as an enterprise-grade ETL predictive analytics platform with a complex UI/UX? Different complexities carry distinct cost implications.
- Required Intelligence Level: What is the sophistication needed in the AI tasks? Whether it’s extracting text and dates from legal documents, diagnosing patient findings from X-ray images, or developing complex algorithms, different tasks call for varying quality standards.
- Data Quality and Volume: Are you working with structured or unstructured data? Consider the necessity for additional or synthetic data, as well as the versions and iterations that may be required.
- Response Metrics: What are the key performance indicators for the quality of responses? Evaluate accuracy, latency, and repeatability early on to avoid scalability issues. Be aware of the trade-offs between quality and cost.
- Scale to Production: Is the solution being used for POC going to be the same system and costs as you forecast costs into full production? Will this be a linear cost of growth with user adoption or will you incorporate the large advancement of cost optimization of AI services and pricing trends?
The following illustration helps to understand the costs and complexity for each AI function domain to improve response accuracy, quality, speed, or costs in the AI enabled application or service.
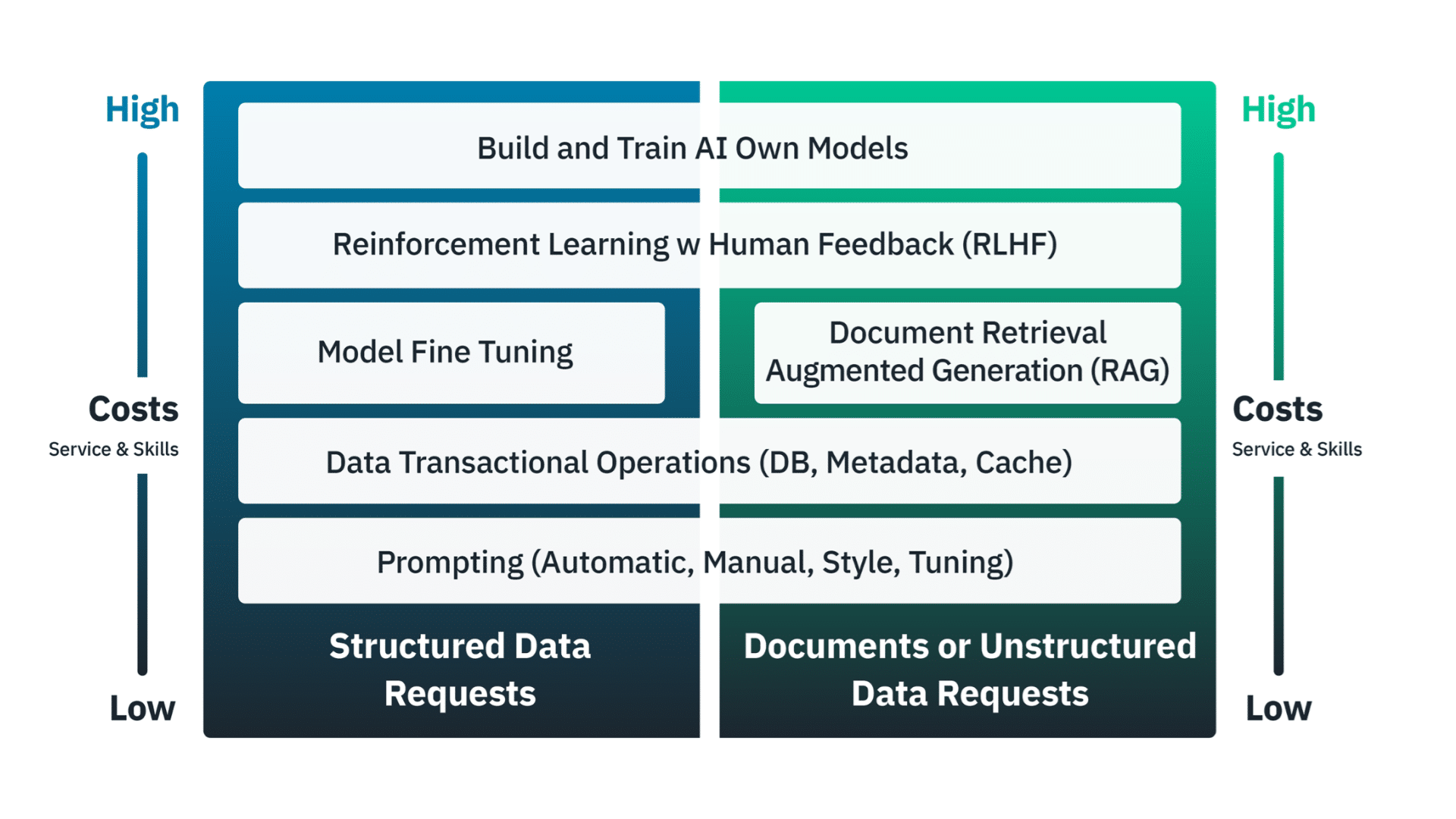
AI services and costs are attributed to a few different domains of functions where quantity and/or rates will be different and enable a more holistic and accurate total spend forecast. Here are some key domains that should be forecasted for need and apply the quantity * rate = cost forecasting approach.
- Prompt Tuning: Manual, Automatic, Guardrails
- Examples Provided in Prompt: Zero shot, few shot for static or dynamic prompt inputs
- Retrieval Assisted Generation (RAG): Facts retrieved and included in prompt input, chain of steps for factual response
- Fine Tuning: Model quality, bias, and iterations and how to deal with hallucinations in POC, stage, prod level maturity
- Reinforcement Learning from Human Feedback (RLHF): Modify reward function for particular outputs schedule and scale of human involvement over time
- From Scratch Model Training: Create own models from training and iterations and cadence where reuse or refinement vs train new costs vs quality/accuracy keep up with pace of innovation
Cost Drivers for Various AI Systems
Understanding what drives the costs of different AI systems is crucial for effective FinOps management. Here’s a breakdown by type:
- 3rd Party Vendor Closed System – Application API SKU usage primary driver
- Costs are primarily based on usage in “tokens in/out” as words of text; plugins and different models may have additional costs for training or setup.
- Dedicated capacity can be available with time period commitment.
- Limited control or ownership over IP.
- Requires the least amount of technical expertise.
- Rates are set per contract terms
- Fewer, mostly PaaS-level SKUs to manage
- 3rd Party Open Model Platform – Infrastructure GPU/RAM capacity commitments and consumption primary driver
- Charges apply for model training.
- Your data volume processed and stored
- Moderate control over IP.
- Requires more technical skills for customization.
- Higher risk of cost overruns.
- You are responsible for managing computational resources.
- Additional SKUs for different elements like model, data, and API calls.
- DIY on Cloud AI System – Infrastructure GPU/RAM capacity commitments and consumption primary driver
- Full control over all aspects of the AI system.
- Complete ownership and control of data.
- Full control over intellectual property.
- Manage SKUs for hardware, software, modeling, training, APIs, and licenses.
- Requires comprehensive technical expertise.
By identifying these cost drivers, you can make more informed decisions that align with your project’s scope, technical requirements, and budget.
AI Pricing Trends
The AI world has been diligently expanding and so has the various methods, tactics, and new tools to produce more mature AI service experiences within the enterprise.
Pricing trends notable to FinOps persona and producing AI forecasts and having to understand the impact to existing spend commits and capacity plans as the engineering leadership is planning or iterating on AI system deployment strategies.
Third-Party Vendors AI services:
- Pricing increase as demand and running costs increase
- Recent large discounts to list pricing announced, prior contracts signed may be reviewed
- Costs for most recent versions of LLM’s/Plugin’s are up to 5-20X more costly than previous versions and context lengths, choose wisely by workload need
- Capacity commitments discounts vary by time, $ and duration and existing pricing agreements
- Large usage requires pre-approved provisioned capacity ahead of time
Cloud Provider Hosted AI Open Models:
- Costs for training dropping fast and significant for training/fine tuning and POC’s.
- Better quality models forcing a race to bottom on narrow task AI LLM specific user stories to take away from leading 3rd party vendors
- Hardware pricing stabilizing for small to medium size deployments, large and very large deployments the GPU resources are still constrained and drive capacity guarantees to assure capacity is available
- New instance CPU/GPU/TPU families generations are higher unit rates vs prior generation for same ratio spec of GB RAM/Cores unit rates.
DIY on Cloud AI systems
- Serverless/GPU Managed middleware services driving costs and skills/effort required down
- Prebuilt model templates/patterns and new partnerships driving down base costs and waste to reduce total costs
- Compute optimizer recommendations already announced to help identify and optimize waste or scheduling/fitting to meaningfully reduce costs
- Adjusting spend commits from RI/Savings Plans/Committed Use Discounts to Spot/Batch or move to managed AI middleware offerings are driving unit costs and total costs down.
All AI services:
- 30x to 200X cost delta from the most expensive leading vendor base user with no optimizations or discounts to a fully engineered for value platform choice where the purchase method and aligned use is fully optimized have already been noted and achieved. The cost delta needs to be taken seriously inside of enterprises when dealing with this large of a cost variance for similar results.
- Inputs prompt techniques and optimizations help assure costs around 15-25% are reduced by using the words “be concise” alone.
- Matching the right technology, platform, configuration, scaling and purchase method as a collective has shown to produce the largest % cost run rate reductions vs a single tactic alone.
- Finetuning, synthetic data generation, and RAG functions costs are reducing as automation continues to mature.
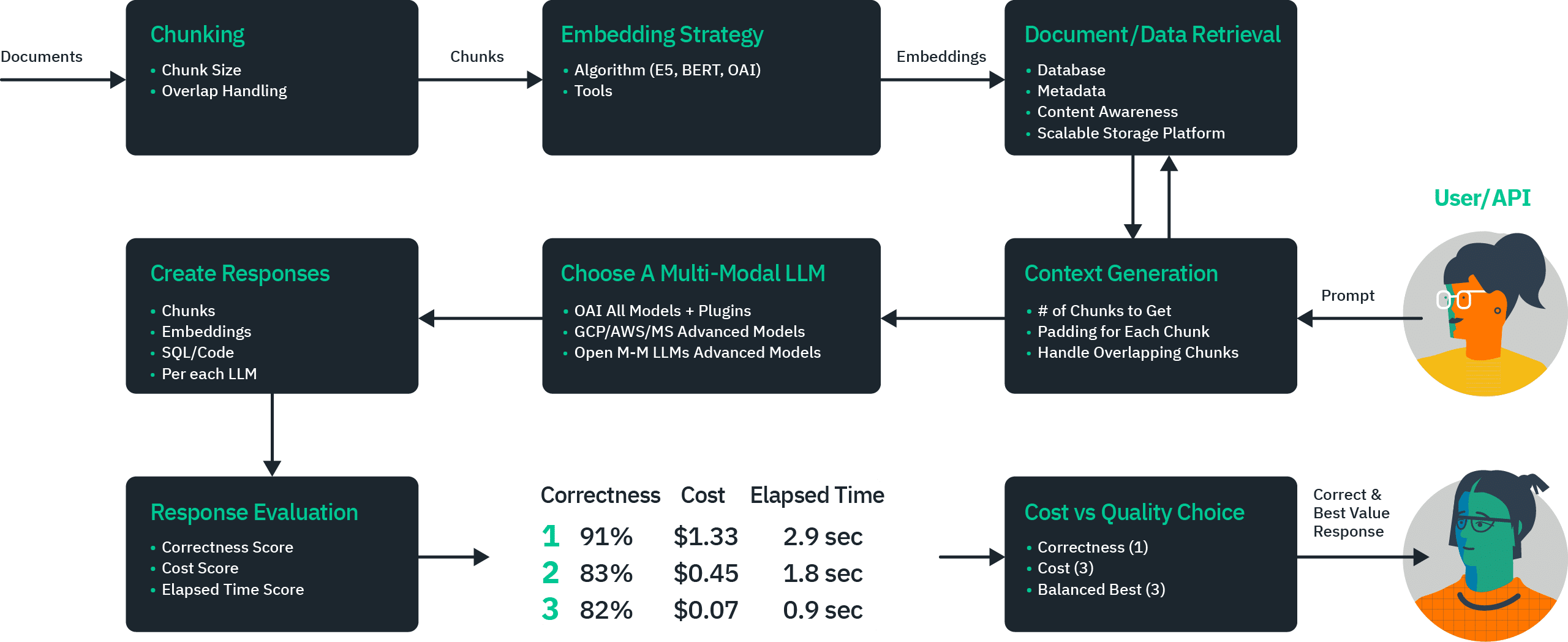
Application Costing Layers Leveraging AI Systems
There are multiple layers of different technology engineering that is required for modern production grade AI enterprise services. The choice is typically associated to a top level Application API total qty of requests into the Commercial AI commercial service as the primary cost estimation driver.
Whereas an enterprise deploying their own open source model text summarization service using cloud provider systems will need to produce cost estimates from the various new layers where AI costs are driven by GPU, RAM, Storage and data processing SKU’s needs.
The below illustration is an example of the many layers and how an engineering team may seek to determine a total cost to operate forecast and begin to evaluate costs, correctness, and performance among different deployment options. The pricing information included is for illustrative purposes only.
Cost Forecasting and Capacity Decisions
AI Forecasting accuracy relies upon proper capacity planning by the business across multiple teams.
The FinOps core team is typically responsible to coordinate the centralized spend commits with the cloud providers and determine the right tradeoffs of risk vs discounted costs by considering existing spend commits with this new AI uptake in similar or different machine types and services.
When AI is being forecasted, the central financial and FinOps spend commit planners should be aware of the FinOps Cloud Forecasting best practices for long term plans and how often these future forecasts will be reviewed and used to plan for spend commits against new AI machine types and services.
Savings Plans/Reserved Instances/ Committed Used Discounts or Contracted capacity with AI vendors needs to be studied and coordinated in order to establish the right rates and forecasting methods in order to properly manage the centralized spend commits and impacts to risk and low/underutilized capacity commitments.
AI spend forecasts are estimates, and with AI being new and pricing still being understood, it should be treated as similar to other enterprise shared services as it is important to have the accurate engineering qty consumption plan understood and follows the FinOps X Video for Cloud Budget and Forecasting best practices as referenced here.
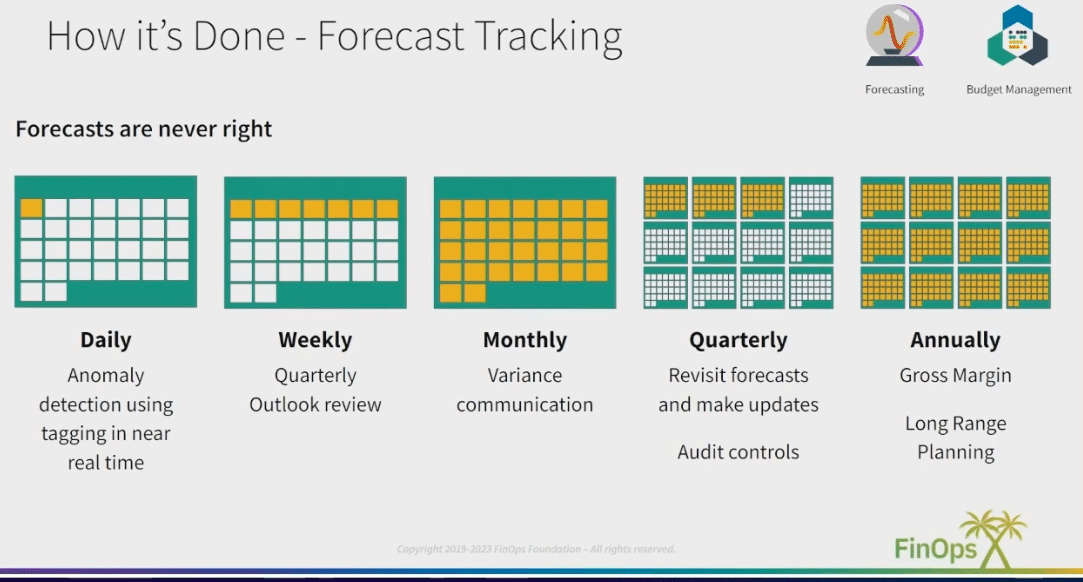
Capacity management issues (service avail, resiliency, network, burst, etc.) impact of commitments early in falling price market
When reviewing third-party API options, there may be multiple ways to access the API which would include on demand (Shared) capacity and provisioned (dedicated) capacity.
On-Demand (Shared) Capacity
- Cost is based on actual tokens processed through the API. Pricing is typically per 1,000 tokens and is specific to token type (prompt and completion). Shared capacity can have inconsistent latency and availability, especially at peak usage times.
- Shared capacity can be used for one time or non-prod/LT applications
Provisioned (dedicated) Capacity
- Provisioned capacity is guaranteed to be available and not shared with other customers.
- Includes a guaranteed amount of throughput (prompt tokens + completion tokens). Provisioned capacity is ideal for production applications sensitive to API latency and availability.
- Pricing for provisioned capacity is charged upfront for provisioned amount (a specific amount of throughput) for one month or longer (e.g. 8,000 tokens per second).
- Cost per 1,000 tokens purchased will be lower than the on demand rates. However, the cost per tokens processed could be higher depending on your utilization.
Considerations
- AI costs are similar to foundation or shared platform costs and the FinOps shared costs should be referenced and reused where applicable
- Services may not scale due to limits in GPU capacity available from providers
- Discounts are meaningful with yearly commit terms. Be aware of the minimum amount of provisioned capacity you can purchase per region or resource, which could be as high as 24,000 tokens per second.
- Vendors should provide a guaranteed range of throughput for provisioned capacity which is a good place to start when deciding on how much to request.
- Some advanced AI services may not be available in all regions at same time
- Are some application’s token consumption constant and others periodic? Timing the periodic usage during non-peak times can help increase utilization.
- AI services should incorporate costs by deployment stage for long term forecasting
- Model for Forecasting or for finance rollup calculation
| Define AI cost
Generally readable. All audiences. |
Agreed definition of what accounts as AI cost, across the entire lifecycle of AI system.
|
AI Cost Challenges
AI cost challenges are top of mind for most organizations when evaluating AI use cases. Of the top five challenges sighted by the ‘Hidden Costs, Challenges, and Total cost of Ownership of Generative AI Adoption in the Enterprise’ findings recently published by Clear ML, three are directly related to cost management.
- Managing overall running and variable costs at scale
- This was the top challenge with firms not considering the total costs of Gen AI at the outset. Key findings include that firms are underestimating the work required to clean data and prepare it to be of value. Additionally they are underestimating the time required by SMEs and failing to adequately budget for run costs once the models are built.
- Improving efficiency and productivity while managing costs and TCO
- Organizations are focused on leveraging economies of scale through multiple use cases and pooling resources in addition to sharing compute power as mechanisms to improve efficiency and productivity.
- Increasing governance and visibility
- The ability to effectively govern AI models to allow effective utilization while limiting unconstrained spend is a key challenge. Visibility and transparency as well as accurate forecasting models for AI costs are critical for long term success.
The other two pertain to oversight and understanding of LLM performance and hiring the specialized talent to effectively build and operate AI capabilities. Understanding these key challenges in advance and taking proactive steps to effectively mitigate cost challenges is critical for the long term success of Gen AI within an organization.
AI Spend Guardrails for Consideration
To ensure effective cost management and operational efficiency in AI deployments, it is essential to establish a set of guardrails. These guidelines act as safeguards to mitigate risks and align the projects with organizational goals.
- Budget Constraints
- POC/Sandbox fixed $ amount or qty of API actions set
- Implement real-time alerts for approaching or exceeding budget thresholds.
- Forecast vs Actuals cost and qty reports self service awareness
- Technical Specifications
- Choose right deployment model and consumption controls
- Disallowed services enforced
- Pre-approvals and IAM permissions established
- Carefully right-size your AI workloads (GPU can be quite expensive)
- Vendor Relationship
- Potential for vendor lock-in, which might be to avoid given the current market (ever changing, lots of development, etc.)
- Committing too much for too long – not giving enough credit to future advancement or optimizations/strategy shifts etc.
- Security and Compliance
- AI usually involve lots of data, need to be careful and follow the established guidelines
- Cross role data sharing violations and permissions controls
- AI provider training on company private data
- Operational Guardrails
- Monitoring and Auditing cost and consumption against thresholds
- Legal, Bias, censorship, or not safe for work input/output results review pipeline
- Performance metrics for accuracy, latency, time to response
- Cost control and optimization policies enforced
By incorporating these guardrails into your FinOps strategy, you can create a more controlled and predictable environment for managing the costs associated with AI systems.
Outcomes and indicators of success
The goals of this working group and paper are to help FinOps practitioners understand what key factors to consider when forecasting the cost of AI services, what to strive for as success measures, and how to achieve business outcomes across engineers plans and the roll up to the financial spend plan where the FinOps team will help with centralized spend commit planning.
Primary Outcomes
- Speedy response times: Reduce total elapsed running time from input to answer completion
- Accurate/Quality of Response: The response should be in context, accurate, and consistent acceptable levels of correctness
- Cost Forecasting Accuracy: The AI forecasts of costs vary only within 5% of actuals per month
- Cost Per Unit of Work: The total unit economic measure for how much the AI service cost to process that amount of work. Cost per day/month in a rate of $/100k words as example
- Cost per GPU Hour: Cost of a GPU per hour unit rate
- GPU Utilization under 100%: GPUs should be using 100% of the GPU or it should be off/scaling and measuring this helps drive total spend committed capacity by machine type/region vs on demand or spot batch approaches to achieve lowest total technical unit rate $/GPU hour
Indicators of Success
- Lower Cost Per Token: Total cost divided by total API requests completed for $/100k tokens
- Latency of response time for answer: Total elapsed time from user submit to full response completed
- Accuracy/Quality of responses: Threshold score of quality of responses against human established correctness baseline.
- Context Length: Abilities to handle larger length of inputs and responses to customers needs.
- Training Cost: Cost to complete a training or fine tuning iteration on a model/chain of steps.
- Forecasting Cadence: The weekly/monthly rolling forecast cadence in AI is ideal in a highly dynamic and high variability cost timeframe to catch runaway or surprise spend fast
Conclusion
AI services are providing significant value and new options for enterprises and organizations to help increase productivity, summarize and recall documents and enable written prompt requests to produce documents, charts, or code as response in seconds. The field is advancing quickly and the cloud providers and AI services vendors are iterating quickly to drive the costs down and the value up. The leading companies are able to build this into their cost forecasting models by accommodating agile and expect the high degree of change in both unit rate costs and the engineering deployment options. With this change comes the need for understanding the different ways to identify the AI cost drivers and produce a cost forecast that is transparent and clear for the right personas to operate and manage AI cloud spend.
The FinOps AI Cost forecasting working group shares the goal and vision to align existing FinOps principles from shared services costing, and platform/tenant and 3rd party service vendor pricing approaches to provide knowledge for FinOps practitioners to consider.
Join and contribute to this rapidly evolving technology by interacting with the FinOps AI slack channel.
Acknowledgements
Thanks to the following people for breaking ground on this asset.

Brent Eubanks
Wayfair
Joshua Collier
Superhuman fka Grammarly
Max Audet
COVEO
Courtney Bormann
General Mills
Yannis Kalfoglou
Dell TechnologiesWe’d also like to thank our supporters: Raj Khanna, David Lambert, Tim O’Brien, Alireza Abdoli, and Abhinav Lad.