Context for Building a FinOps Practice for Data Cloud Platforms
Summary: Data Cloud Platforms (like Snowflake, Databricks, BigQuery) bill differently than traditional public clouds, focusing on units like queries run, data scanned, or virtual currency (credits/DBUs), making cost control about workload efficiency, and not just switching off servers. Build in FinOps for Data Cloud Platforms by establishing a detailed Allocation strategy that correlates ephemeral compute, shared resources, and transient workloads to specific teams or projects using job-level tracking and custom metadata. Tune queries, implement rightsizing of shared resources (warehouses/clusters), and use commitment purchases (like reserved slots) that are accurately matched to actual usage patterns.
Data Clouds—like BigQuery, Amazon Redshift, Microsoft Fabric, Snowflake, and Databricks—bill very differently from traditional public clouds. Instead of paying for servers by the hour, you pay for things like queries run, data scanned, virtual currency units (credits, DBUs, slots), and how many workloads run at once. That means cost control is less about switching things off and more about making workloads efficient—tuning queries, reducing unnecessary scans, scheduling jobs at the right time, and matching commitment purchases (like slot reservations or capacity bundles) to actual usage.
It’s also harder to see exactly who is driving the costs. Shared compute and short-lived jobs make it tricky to link spend back to specific teams, dashboards, or projects without detailed tracking. Since these workloads often involve analytics and AI, FinOps needs to work closely with data engineers, data scientists, and platform teams to build cost awareness into their daily work. In Data Clouds, controlling cost is a team effort—and the team looks different from traditional FinOps.
What is a Data Cloud?
A Data Cloud is a flexible, managed platform for storing, processing, and analyzing large volumes of diverse data. It evolved from traditional data warehouses to meet growing data demands, offering a unified, high-performance foundation for modern analytics.
By separating storage and compute, using massive parallel processing, and hiding infrastructure complexity, a Data Cloud enables real-time analytics, scalable machine learning, and seamless integration across hybrid and multi-cloud environments—things that weren’t possible before the cloud.
Depending on the overall data cloud vendor selections and wider data architecture choices the following characteristics could apply:
Cloud-Agnostic Overlay
Modern data cloud platforms operate across public cloud, private cloud, and on-premises environments. They hide the complexity of the underlying infrastructure, allowing teams to access, manage, and process data consistently, regardless of where it lives. This flexibility helps meet data residency requirements, improve system reliability, and optimize workload performance.
Unified Metadata and Governance
A centralized metadata catalog and policy engine standardizes how data is defined, accessed, and governed. This ensures consistent application of data quality, security, and compliance policies across the organization, while still enabling teams to explore and use data through self-service tools.
Multi-Modal Workloads
Data clouds support different types of workloads—transactional, analytical, streaming, and machine learning—on the same data. This eliminates the need to move or reformat data between systems. Teams can run the right compute engine when needed, improving both agility and cost-efficiency.
Real-Time and Event-Driven Processing
Many data clouds have built-in support for real-time data sources, including change data capture (CDC), message queues, and streaming platforms. This allows organizations to ingest data continuously and run near-instant analytics, enabling faster and more responsive decision-making.
Pay-As-You-Go Economics and Automation
Data cloud platforms typically scale compute and storage resources automatically based on demand. This allows teams to avoid the cost of idle infrastructure. Because compute and storage are billed separately, organizations only pay for what they actually use, improving financial efficiency.
Virtual Currency Abstraction
Some platforms use their own units of account—like credits, tokens, or database units—instead of direct billing. While these simplify internal pricing models, they also make cost tracking and forecasting more complex. FinOps practitioners need new methods to translate this usage into meaningful cost insights.
Embedded Security and Compliance
Security features such as encryption, role-based access controls, audit logging, and data masking are built into many data clouds. These features help organizations meet compliance requirements and protect sensitive data without requiring custom development or manual enforcement.
Shared Ownership and Cost Complexity
Data clouds often serve multiple teams or departments from shared infrastructure. This shared model makes it harder to assign costs to specific users or outcomes. Accurate cost attribution requires detailed tracking, including metadata tags and usage logs tied to specific jobs or teams.
Activating AI in Organizations
Data clouds provide the infrastructure to support artificial intelligence and machine learning at scale. With built-in tools for data preparation, model training, and real-time inference, teams can automate tasks and generate insights quickly—especially when supported by a strong data strategy.
FinOps Framework – Building a FinOps Practice for Data Cloud Platforms
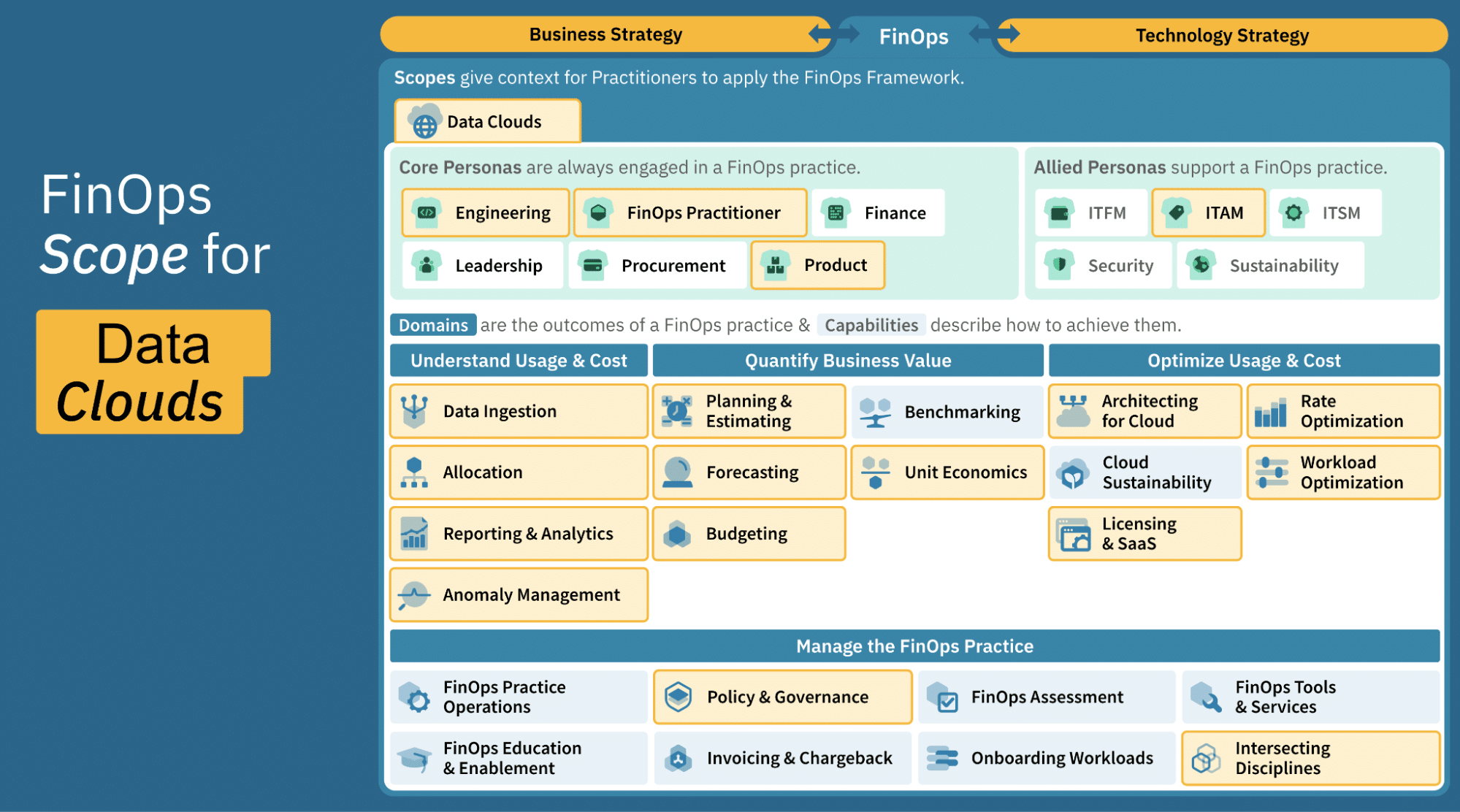
FinOps Capability Considerations for Data Cloud Platforms Practice
Data Ingestion
- Identify & onboard key sources: Ingest usage and billing exports for batch, streaming, Change Data Capture (CDC) (e.g., Snowflake Account Usage views, Databricks billing & audit logs, AWS Cost & Usage Reports, Azure Cost Management exports, GCP Billing export tables), including auto-scaling events (Databricks autoscaling, Snowflake warehouse resizing), performance logs, and storage consumption per service.
- Normalize across platforms & currencies: Normalize consumption data using a unified schema (e.g., FOCUS standard) to abstract variances in platform units like Snowflake credits, Databricks DBUs, AWS EC2 instance hours, Azure vCore hours, or GCP BigQuery slot-minutes.
- Standardize cost data using currency conversions for multi-region or global deployments. Map platform-specific resources and storage tiers (e.g., S3/Blob/GCP storage buckets, Snowflake storage, Databricks DBFS) to common logical groups.
- Integrate context: Enrich dataset by integrating cloud-native tag/label data (Snowflake object tags, Databricks workspace tags, AWS resource tags, Azure resource groups/tags, GCP labels) for filtering and reporting by business dimension (team, BU, environment, cost center, project).
- Ensure data quality & consistency: Validate schema changes, enforce tag/label completeness (e.g., blocking untagged resource creation in AWS/Azure/GCP policies).
- Maintain timeliness & availability: Schedule daily (or more frequent) exports of usage snapshots, stream CDC-style logs (e.g., audit, query history, etc.), and monitor lag against SLAs.
Allocation
In data cloud environments, IT must account for ephemeral compute, shared resources, and transient workloads, requiring job-level tracking and metadata correlation to ensure accurate cost attribution.
- Maintain an allocation strategy: Decide the unit of showback/chargeback (warehouse, cluster, job, query, database, project). Align it to business hierarchies so every dollar is traceable back to a workload or team. Support showback/chargeback by associating technical consumption with business context.
- Tagging, naming conventions & hierarchy strategy: Enforce tags/labels at creation and bake into IaC templates; ensure they persist through ephemeral clusters and serverless tasks. In data clouds, accurate attribution also needs job-level tracking, tagging, and metadata correlation to link transient resources and queries to the right teams.
- Shared cost strategy: Identify charges that span teams (e.g., cloud storage buckets, data lake, AWS S3, Google Storage, Azure Storage Account, Kafka topics, networking egress). Choose fixed, proportional or usage-based split rules and automate monthly reallocations.
- Validate compliance: Continuously detect and remediate untagged or misattributed jobs, warehouses, or queries — especially in ephemeral or auto-scaling environments where resources can appear and disappear within minutes — to maintain reliable allocation and chargeback accuracy.
Reporting & Analytics
While the core FinOps reporting principles remain unchanged, data cloud environments require integration with platform-specific telemetry and billing APIs, along with normalization across different virtual currency units (credits, DBUs, slots).
- Centralize usage and cost data: Leverage native integrations and APIs from Snowflake (Account Usage views, Information Schema), Databricks (Audit Logs, Cluster Metrics), AWS (Cost and Usage Reports, CloudWatch metrics), Azure (Cost Management exports, Monitor logs), and GCP (Billing export tables, Stackdriver monitoring) to ingest the most granular, platform-specific usage and cost data. Aggregate this data continuously into a unified data warehouse—such as Snowflake, Databricks, AWS Redshift, GCP Bigquery, Synapse Analytics —establishing a single source of truth across multi-cloud environments.
- Build personas-based views: Create customized, role-specific dashboards leveraging BI tools or native solutions (e.g., Snowflake dashboards, Databricks SQL Analytics, AWS QuickSight, Azure Power BI, Google Looker) for example: Engineers (e.g., top queries, job runtimes), finance (e.g., unit costs, spend trends), and product owners (e.g., cost per feature/team).
- Enable self-service access: Provide semantic models and query templates so stakeholders can explore their own cost and usage data without needing deep platform knowledge.
- Unify metrics and units – Normalize compute metrics to a standard cost-per-unit model for analysis (e.g., FOCUS consumed unit) so cross-platform reporting is comparable.
Anomaly Management
Anomaly management in data clouds places greater emphasis on query- and workload-level behaviors (e.g., inefficient SQL, heavy joins, concurrency bursts) while still monitoring infrastructure factors such as warehouse sizing, idle clusters, and storage tier changes. Granular spend data and platform context are key to separating genuine cost risks from expected elastic activity.
- Detect cost spikes quickly: In data clouds, anomalies often stem from query-level events like inefficient SQL, heavy joins, or sudden concurrency bursts. Track spend at the most granular level (credits, DBUs, slots) and compare it to historical baselines, factoring in auto-scaling and scheduled data refreshes to avoid false positives.
- Correlate with orchestration logs: Match anomalies with runs in orchestration tools like Airflow or Dagster to confirm if the spike came from a planned job (e.g., full refresh, backfill) or an unexpected process.
- Flag unusual virtual currency burn rates: Highlight cases where burn per query, per job, or per concurrency level deviates sharply from the historical median — even if total spend is within budget.
Planning & Estimating
- Understand platform-specific pricing models: Account for per-second or per-query billing, virtual currency units, and decoupled storage/compute when modeling cost.
- Incorporate workload characteristics: Plan for different consumption patterns such as long-running pipelines, bursty ML jobs, or high-concurrency BI queries.
- Build a cross-functional forecasting strategy: Engage FinOps personas to agree on the modeling horizon, KPIs, and acceptable variance thresholds.
- Use historical usage as input: Analyze previous credit, DBU, or slot usage trends to estimate future demand and cost under various scenarios.
- Factor in architectural decisions: Include scaling policies, cluster sizing, and warehouse configurations into estimates.
- Build scenario models: Create “what-if” models to estimate cost impact of new features, increased concurrency, or migration to different pricing tiers or clouds.
- Tie spend to business value: Align spend plans with business outcomes such as new feature delivery, analytics adoption, or AI/ML initiatives, to maintain focus on value creation rather than pure cost control.
Forecasting
Forecasting in data cloud environments requires modelling virtual currency consumption (credits, DBUs, slots) and linking it to workload patterns, concurrency, and elasticity to produce accurate, actionable projections.
- Map virtual currency to workloads: Track burn rates for Snowflake credits, Databricks DBUs, or BigQuery slots and tie them directly to query types, concurrency levels, and scheduling patterns to reveal which workloads or teams are driving consumption, identify inefficient query behavior early, and forecast costs in business-relevant terms.
- Incorporate elasticity behavior: Factor in cost fluctuations from auto-scaling warehouses, dynamic cluster sizing, and bursty workloads triggered by data refreshes or concurrent access.
- Separate storage vs. compute trends: Storage (tables, materialized views, staged data) often grows steadily, while compute usage is highly volatile; forecast them independently.
- Scenario modeling for query patterns: Build what-if models to simulate the impact of increased concurrency, heavier joins, or new ML/ETL jobs.
- Rolling forecast cadence: Update forecasts monthly (or more often) to reflect real-time workload behavior shifts.
Budgeting
Budgeting in data cloud environments it requires conversion mechanisms to translate virtual currencies (credits, DBUs, slots, node-hours) into monetary values for actionable financial oversight.
- Set budgets aligned to consumption units: Create budgets based on platform-specific pricing models: credits (Snowflake), DBUs (Databricks), slots (BigQuery), and node-hours (Redshift). Separate compute and storage budgets where applicable.
- Define scope-specific budgets: Allocate budgets at the right level (teams, projects, environments, or business units) and align to cost attribution strategies for shared or multi-tenant resources.
- Monitor and track in real time: Enable near real-time budget tracking using native cost views and integrate with alerting tools to notify stakeholders as thresholds are approached.
- Automate budget enforcement when possible: Use platform-native controls to prevent runaway costs beyond budgeted thresholds.
Unit Economics
Normalize diverse cost metrics—like Cost per Query, Job, Pipeline, or TB Scanned—into consistent unit economics. Track key ratios (e.g., TB Scanned/TB Stored) to flag inefficiencies, and measure hardware idle time to improve utilization. This enables cost-per-output insights critical for optimizing Data Cloud workloads.
Architecting for Data Cloud
Regarding data clouds, compute and storage are decoupled, with ephemeral and auto-scaling behavior. Architecture decisions directly impact cost visibility and control.
Refresh rate is a huge factor in costs with data “freshness” a key consideration.
Avoiding redundant data pipelines by maintaining a data catalog.
Design Data Clouds with built-in cost awareness for data residency, compliance, and encryption—especially across regions. Unlike general cloud, Data Clouds often incur added costs for storing and processing sensitive data in specific geographies or under stricter controls.
Workload Optimization
Optimization in data cloud platforms is a major cost driver, requiring a shift from traditional FinOps techniques to platform-aware strategies. Approaches vary significantly across Data Clouds but generally should consider:
- Tune ephemeral compute: Monitor job and query behavior over time to right-size clusters or warehouses, avoiding persistent over-provisioning.
- Target inefficient jobs: Use query history or job lineage to spot costly patterns (e.g., nested joins, large scans) and remediate them.
- Control bursty workloads: Identify and manage spikes from ML training, AI inference, or other workloads that trigger unexpected GPU use or aggressive auto-scaling.
- Group jobs for scheduled execution: Batch compute-intensive jobs to reduce startup overhead and leverage predictable volume patterns.
- Rightsize hardware/warehouses: Match hardware or warehouse size to workload needs; consolidate resources across teams for higher utilization, scaling only when necessary.
- Address shared-resource complexity: Overcome challenges like delayed billing data and ephemeral workloads by using deep job-level insight to detect inefficiencies or idle usage early.
Rate Optimization
In most data clouds, rate optimization shifts from traditional reserved instance management toward commitment-based constructs such as credit bundles, DBU plans, or slot reservations. These platforms price in credits, DBUs, slots, or capacity units, often with limited transparency. Opportunities for negotiation and optimization exist but are harder to benchmark.
- Understand commit unit mechanics: Snowflake’s Capacity Units (CUs) and Databricks’ DBUs don’t map 1:1 with workload time or size. FinOps teams must decode how warehouse size, job duration, concurrency, and query type drive consumption before making commit decisions.
- Align workload patterns to commit drawdown: Some workloads (e.g. ELT refreshes, ML retraining) consume disproportionately more credits or slots than expected. Use historical burn patterns at the query/job level to inform sizing — not just total monthly usage.
Policy & Governance
Governance frameworks in data cloud environments must adapt to data-specific policies, shared compute models, and platform-native controls to ensure both compliance and agility at scale. Unlike traditional cloud, challenges often stem from multi-tenant workloads, limited native tagging, and the need for consistent metadata across jobs, warehouses, and datasets.
- Address tagging and metadata gaps: Many data cloud platforms (e.g., Snowflake, Databricks) lack built-in tagging for all resources. Enforce metadata standards — workload name, owner, environment, business unit — at job or warehouse creation.
- Establish cost ownership in shared environments: Require explicit team or user mapping when provisioning shared warehouses or clusters to prevent “orphaned” spend.
- Set workload lifecycle policies: Apply platform-native controls such as auto-suspend, TTL for clusters, query timeout limits, and storage lifecycle rules to prevent runaway costs or stale resources.
- Enforce platform-specific guardrails: Use workload isolation, resource quotas, and permission boundaries to balance performance with budget limits.
Ensure metadata visibility: Use FinOps FOCUS 1.2 as a baseline to verify that the platform exposes the necessary usage and cost attributes for accurate reporting and governance.
Personas/Intersecting Disciplines
New actors like data engineers, data scientists, and ML teams influence spend without traditional accountability. FinOps must engage beyond traditional personas and associated roles, identifying where they sit in the organizational structure to collaborate with.
Leadership
- Chief Data Officer (CDO): Owns enterprise data strategy, governance, and alignment of platform investments to business objectives. Supports cross-functional collaboration on cost and performance trade-offs.
Engineering & Platform Roles
- Data Engineers: Manage data ingestion, pipeline orchestration, performance tuning, and warehouse optimization. Key in tuning ephemeral compute and preventing inefficient workloads.
- Data Scientists / ML Engineers: Build and deploy predictive models, ML workflows, and advanced analytics. Cost impact comes from model training, inference workloads, and GPU usage.
- Platform Administrators / Data Architects: Oversee platform governance, security, user access, and cost controls. Collaborate with FinOps to enforce quotas, tagging, and lifecycle policies.
- DataOps / Platform Engineering Teams: Handle cluster configuration, logging, and cost-aware provisioning, ensuring infrastructure matches workload needs.
Product & Analytics Roles
- Data Analysts: Develop models, run SQL queries, and produce reports. Partner with FinOps to measure cost-to-value (e.g., cost per dashboard, cost per dataset).
- Business Users / Executives: Consume dashboards, reports, and insights for decision-making. Need clear visibility into cost-to-business-value metrics.
- Product Managers / Analytics Teams: Define and track metrics like cost per feature or ML model to link spend with business outcomes.
Allied & Governance Roles
- Security & Compliance: Manage data privacy, security policies, and governance frameworks to meet regulatory requirements.
- IT Financial Management (ITFM): Integrate data cloud costs into broader budgeting and forecasting. Ensure spend visibility for Snowflake, Databricks, and other platforms alongside existing cloud services.
Enablement Across Personas
- Upskill new personas (engineers, scientists, analysts) on cost impact through onboarding materials and in-platform awareness campaigns.
- Establish shared KPIs and dashboards so each persona can see their contribution to spend and efficiency.
Understanding Data Cloud Types
To apply FinOps effectively, it’s important to understand the types of Data Clouds and how they work. Their architecture affects usage patterns, who’s involved, and how FinOps practices are applied.
Data Warehouse
Structured, high-performance analytics platforms that decouple compute and storage. Designed for fast queries on large volumes of structured data.
Common Vendors:
- Snowflake
- Databricks
- Amazon Redshift
- Google BigQuery
- Microsoft Azure Synapse Analytics
- Microsoft Fabric
- SAP HANA, Oracle Database (licensed/on-prem-style deployments)
- Oracle, Oracle Cloud Infrastructure (OCI) Data Platform
- Alibaba Cloud AI and Data Intelligence
Cost Behavior:
- Usage-based billing by credits, slots, or per-second execution
- Costs tied to query frequency, concurrency, and cluster size
- Difficult to forecast due to dynamic workloads (e.g., ad hoc dashboards)
Data Lake
Storage-first architecture for raw or semi-structured data. Compute is often pay-per-scan or brought in through query services.
Common Vendors / Stack Examples:
- Amazon S3 + Athena
- Google Cloud Storage + BigQuery
- Azure Data Lake Storage + Synapse or Fabric
Cost Behavior:
- Low-cost storage, high variability in compute costs
- Charged by volume scanned or data ingested
- Partitioning and file format (e.g., Parquet, ORC) significantly affect cost
Lakehouse
Combines features of lakes and warehouses—open storage formats with warehouse-like compute and governance.
Common Vendors / Tools:
- Databricks (Delta Lake)
- Snowflake (Iceberg)
- Google BigQuery (materialized views + streaming)
- Microsoft Fabric
- Oracle Cloud Infrastructure (OCI) Data Platform
Cost Behavior:
- Hybrid pricing models: compute jobs + streaming + storage
- Complex workflows (e.g., notebooks, pipelines, SQL) driving cost unpredictability
Enterprise Platforms
Stateful, licensed systems embedded in enterprise environments. Often act as upstream data sources or hybrid extensions.
Common Vendors:
- SAP HANA
- Oracle Databases & Heatwave
- Microsoft SQL Server
Cost Behavior:
- License-based with underlying infrastructure costs
- Limited visibility due to missing APIs or tagging
- Capacity-based pricing with minimal elasticity
A FinOps practitioner may also come across other data technology types within and overall enterprise data architecture, such as:
- Streaming Platforms e.g. Kafka, Kinesis, Event Hubs – these are not standalone data clouds but essential real-time ingestion layers within a data cloud
- ETL/ ELT Tools e.g. dbt, Fivetran, Airbyte – these are considered integration layers
- ML/ AI Platforms e.g. Sagemaker, Databricks ML, Copilot Studio – these can be part of a data cloud when tightly integrated with storage and compute layers and will be considered in subsequent papers in line with applicable use cases
- Orchestration Platforms e.g. Apache Airflow, AWS Step Functions, Data Factory, Power Platform.
Data Cloud Integration Patterns
To apply FinOps to Data Clouds, it’s key to understand how your architecture affects costs. Many environments blend data warehouses, lakes, and lakehouses, often with overlapping tools in the wider technology data architecture. Without a clear view of how these systems connect, cost tracking and optimization become difficult.
FinOps teams should map the full data architecture, highlight what’s integrated or siloed, and apply Data Cloud specific consideration of FinOps capabilities like allocation, forecasting, and optimization accordingly.
Most organizations follow one of four common patterns:
- Hub-and-Spoke: A central data lake feeds multiple tools.
- Federated: Independent data platforms with shared governance.
- Consolidated: One main platform to reduce complexity and cost.
- Hybrid: On-prem systems integrated with cloud, mixing cost models.
These patterns shape pricing models and cost drivers.
Data Cloud Pricing Models
This table is focused on examples on how the costs are billed by vendors in the data cloud landscape.
Consumption-based
| Typical Usage Cases | Compute runtime (per sec/min), Storage per GB/month, API requests |
| Vendor Examples | AWS EC2, AWS S3, GCP, Azure, Databricks |
| Key Nuances & Architecture Impact | Linear scaling; spot/preemptible pricing available; some BYOL support |
FinOps Action: Monitor spikes; automate idle resource shutdown; watch for hidden costs.
Tiered Pricing
| Typical Usage Cases | Storage volume ranges, Data transfer bandwidth |
| Vendor Examples | Snowflake storage tiers, Databricks volume discounts |
| Key Nuances & Architecture Impact | Volume discounts after thresholds; multiple storage classes (hot, cold, etc.) |
FinOps Action: Forecast volumes; automate tier movement.
Commitment / Reserved
| Typical Usage Cases | Compute cluster capacity reserved ahead |
| Vendor Examples | Snowflake reserved capacity, AWS/Azure RIs |
| Key Nuances & Architecture Impact | Discounted rates with upfront commitment; risk of unused capacity |
FinOps Action: Review utilization regularly; adjust commitments accordingly.
License-based
| Typical Usage Cases | Feature sets, concurrency licenses |
| Vendor Examples | Snowflake Enterprise, Databricks Premium |
| Key Nuances & Architecture Impact | Fixed fees per license; may limit concurrency or feature access |
FinOps Action: Audit licenses; avoid over-provisioning.
Hybrid-embedded
| Typical Usage Cases | BYOL offerings, embedded infrastructure |
| Vendor Examples | Oracle OCI BYOL, Azure hybrid deployments |
| Key Nuances & Architecture Impact | Use existing licenses with cloud infra; integration complexity |
FinOps Action: Optimize BYOL usage; consider vendor support requirements.
Primary cost drivers
Vendor and architectural choices can result in overlap or convergence, making it essential to understand the specifics of your environment to identify which cost drivers apply. For example, Vendor A may include data transfer within storage pricing, while Vendor B may bill it separately.
Storage
| Primary Cost Drivers |
|
| Cost Driver Summary | Charges depend on total volume, retention policies, and frequency of access |
| Data Cloud Type Mapping |
|
FinOps Consideration: Use lifecycle policies, avoid unnecessary retention, and use cold/archival tiers.
Compute
| Primary Cost Drivers |
|
| Cost Driver Summary | Cost grows with processing time, scale, and specs |
| Data Cloud Type Mapping |
|
FinOps Consideration: Use autoscaling/spot – Monitor concurrency limits.
Data Transfer
| Primary Cost Drivers |
|
| Cost Driver Summary | Charges primarily on outbound volume, region, and pattern |
| Data Cloud Type Mapping |
|
FinOps Consideration: Minimize egress, use caching/CDNs, and optimize data locality.
Other / Ancillary Services
| Primary Cost Drivers |
|
| Cost Driver Summary |
|
| Data Cloud Type Mapping |
|
FinOps Consideration: Track API/licensing usage, automate orchestration, and match licenses to real use.
Multi-Modal Billing Models
Modern data platforms are designed to support a wide range of use cases—data engineering, analytics, machine learning, real-time processing, and business intelligence—across organizations of varying sizes and maturity levels.
To address these diverse needs, vendors often provide multiple billing models within a single platform. While this approach offers flexibility to align with workload patterns and consolidate different types of operations, multi-modal billing models can also introduce confusion, complexity, and wasted spend. Common challenges include:
- Difficult to forecast accurately – particularly without historical usage patterns.
- Selecting the right model requires deep architectural understanding.
- Managing capacity allocations (e.g., Microsoft Fabric CUs or Redshift RPUs) can become operationally burdensome.
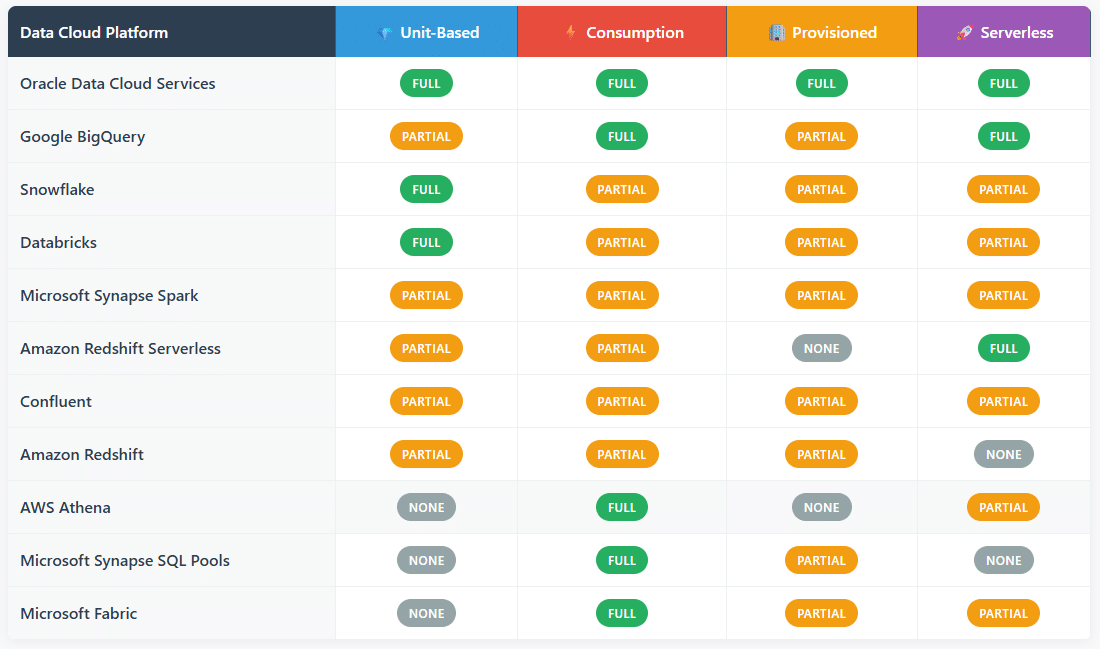
Key for Data Cloud Platform Table
| Pricing Model | Applicability | Reason |
| Unit-Based (e.g. Cost per Query, per Job, per User) | Full | Common in analytics and ML workflows; aligns with granular billing for actions like queries, model runs, or API calls. Enables cost attribution at workload or user level. |
| Consumption-Based (e.g. $/TB scanned, $/hour) | Full | Core model for many serverless and MPP (Massively Parallel Processing) services. Supports elasticity and auto-scaling. |
| Provisioned (e.g. reserved compute, warehouse size) | Partial | Often used in predictable workloads or for performance guarantees (e.g. Snowflake warehouses). Less flexible but sometimes cheaper with sustained use. |
| Serverless (on-demand, auto-scaled) | Partial | Increasingly available across Data Cloud platforms, but not always supported for all services or regions. Ideal for bursty, unpredictable workloads. |
RACI: Responsible, Accountable, Informed, Consulted
This section outlines potential roles and responsibilities of the FinOps practitioner for Data Clouds, as well as intersections with other personas and disciplines—whether establishing cost visibility for BigQuery, managing pipeline sprawl on Databricks, or allocating Snowflake spend across business units.
While the scope of FinOps varies based on Data Cloud architecture, provider, and organizational setup, this paper presents a set of high-level activities to guide teams. The RACI matrix provided is intended as an illustrative example rather than a prescription or best practice, showing where different roles and responsibilities may reside.
| Key Activities (Not Exhaustive – will differ by organization) | Leadership
(CDAO) |
FinOps Practitioner | Engineering (Cloud Data Engineer, DBA) | Engineering
(TechArch) |
Finance | Product | Procurement |
| Internal use case estimation (similar to cloud migration estimate) | |||||||
| Virtual currency budget setting | A | C | R | I | I | ||
| Warehouse/cluster rightsizing | C | R | I | A | I | ||
| Cost allocation methodology | R | C,A | A | C | I | ||
| Commitment purchase decisions | R | C | A | I | R | ||
| Workload Optimization Initiatives | R | C | A | I | I | I | |
| Data/ Query optimization Initiatives | C | A | R | I | C | I | |
| Forecasting and Budgeting | I | C | R | R,A | R | C | I |
| Data Governance and Initiative Planning | A | C | R | R,A | I | I | C |
| Data Retention & Archiving | A | C | R | I | I | I | |
| Data Lifecycle Management | A | I | R | C | I | I |
Strategic and tactical decisions, such as whether to buy or build a Data Cloud, renew an existing tool, look for alternatives, or completely discontinue, are often made in a group setting where the representatives of different areas make a joint decision.
Conclusion
Think of traditional cloud FinOps like managing a fleet of rental cars where each vehicle has a clear hourly rate and direct usage tracking. Data cloud FinOps, however, resembles managing a complex transportation network where costs flow through virtual currencies, resources are shared dynamically, and billing reflects consumption patterns rather than simple resource allocation.
Data cloud FinOps represents a strategic imperative for data-driven business transformation. Organizations developing these specialized capabilities achieve competitive advantages through better cost management, faster innovation, and enhanced ability to scale data initiatives while maintaining financial discipline throughout their digital evolution.
Acknowledgments
We’d like to thank the following people for their work on this Paper:

Cory Syvenky
Teck Resources Limited
Rich Young
Warner Leisure Hotels
Robert Nieuwenhuizen
McKinsey
Lorant Kiss
Delivery Hero
Priyanka Pandey
Delivery Hero
Simarpreet Arora
Snowflake
Marcos Tipacti
JPMorgan Chase
Marcos Palma
Oracle
Frank Contrepois
FinOps Lead
Rich Gibbons
Synyega
Ermanno Attardo
Trilogy
Josh Bauman
Apptio, an IBM Company
Alessandro Bellini
Max Mara Fashion Group
Daniel Whitefield
Certero
Muthuraman Annamalai
FanDuel
Sudama Prasad
Glencore UK