FinOps for AI Overview
Summary: New usage metrics like cost-per-token and awareness of volatile costs and GPU scarcity bring new challenges. Regularly track and review AI costs and usage, set quotas, tag resources, and optimize GPU allocation to tightly control AI spending. Train teams on FinOps best practices for AI and align real-time financial monitoring to business outcomes for continuous improvement.
On this page:
- Fundamentals of AI-driven Apps in Cloud Environment
- Measuring AI’s Business Impact
- Best Practices for Performing FinOps on AI Services
- Building Incrementally: Crawl, Walk, Run of managing AI Costs
- KPIs and Metrics
- Regulatory and Compliance Considerations
- AI Scope Mapping to Framework
- Acknowledgments
New AI cost and usage challenges, same FinOps approach
Organizations across industries and technology maturity levels are exploring Generative Artificial Intelligence (Gen AI) services such as Large Language Models (LLMs), to augment their products, enhance employee productivity, and deliver greater value to customers. These services introduce new challenges and opportunities to FinOps teams.
Some of these challenges are the same as those for the adoption of any new technology architecture or application model, and some are unique to AI.
Like any new technology a FinOps practice takes on, AI requires learning new terminology and concepts, collaborating with new stakeholders, and understanding spending and discounting models to optimize. However, AI brings specific challenges managing specialized services, GPU instance optimization, specialized data ingestion requirements, and the broader (and faster) impact of AI cost on more diverse cross-functional teams.
Although AI/ML services have existed for years, their implementation historically required significant effort and expertise. Recent advancements from cloud providers and AI vendors have drastically simplified the deployment of Gen AI services, driving a surge in demand for GPU-based hardware, scalable cloud services, and skilled professionals capable of designing and managing these systems.
This accessibility has led to non-traditional groups—such as product, marketing, sales, and leadership—directly contributing to AI-driven expenses. At the same time, the scarcity of GPUs has created a volatile infrastructure market, while diverse implementation models and cost structures make achieving FinOps goals—such as Understanding Usage & Cost and Quantifying Business Value—more complex.
Fundamentals of AI-driven apps in a cloud environment
How AI Services are managed like other clouds
Gen AI services may at first seem entirely novel, with new terminology and concepts, but they are often managed like other cloud services. For the FinOps Practitioner, it is important to keep in mind that there are many similarities to other cloud services that you manage, and in many ways, your current FinOps practice can begin to manage Gen AI cost and usage with your current approach.
- Basic Price * Quantity = Cost equation still applies. Practitioners can manage cost by reducing Price (Rate) or reducing the amount of resources used (Quantity)
- Cloud-based AI service costs appear in Cloud Billing data alongside all other cloud costs. You may need to consider other Data Ingestion for other technology vendors’ data, or from observability systems specifically tailored to AI services
- Tagging/Labeling of services is possible for many cloud services to support allocation. Some adjustments to these for shared environments, training costs, or API-based resources may be required.
- Many AI service components are eligible for Commitment Discounts (Reservations) and your Rate Management processes are very similar to traditional cloud services
How AI Services are managed differently
Gen AI services can introduce challenges that are different from most other public cloud costs:
- Many AI models and services charge inconsistently, and may be purchased in many versions or variants. Pricing may change wildly up or down.
- Cloud providers create new SKUs regularly, many without ability to tag natively and require engineering tooling to enable tag key:values for cost splitting/tracking for application Total Cost of Ownership (TCO) of tenant usage
- Names and types of services can be very different from those currently managed by your FinOps team.
- Tokens! The meters, or elements of charge can be very different. For example, measuring the tokens at the user input vs. the compressed and semantic reduced or re-written actual prompt input token quantity that goes to the API endpoint that is charged. Further explanation can be found here in this paper on usage tracking.
- Scarcity of AI infrastructure resources and service availability is typical with GPU-based servers and needs to have capacity management techniques applied for contractual, orchestration, and purchase methods which is less often seen with traditional cloud services which affects availability and pricing of infrastructure.
- Engineering teams are immature in their use of AI services and the many dynamic layers needed to achieve ongoing cost effectiveness.
- Understanding the TCO of AI use cases can be different than traditional software application workloads’ fixed costs and purpose, where continuous training is part of the ongoing cost as the quality dimension is a key new aspect to consider into the need as to using smaller cheaper new models to meet same minimum quality, or requires most advanced reasoning leading edge foundation models for human like advanced quality.
Generative AI use has created an entire tech stack of services from major cloud providers to support a wide variety of use cases.
| GenAI Category | GenAI Component | Amazon Web Services | Google Cloud | Microsoft Azure |
| Foundation Models | Runtime | Amazon Bedrock | Vertex AI | Azure OpenAI |
| Text / Chat | Amazon Bedrock | PaLM | GPT | |
| Code | Amazon Q, Amazon Bedrock | Codey | GPT | |
| Image Generation | Amazon Bedrock | Imagen | DALL-E | |
| Translation | Amazon Bedrock | Chirp | None | |
| Model Catalog | Commercial | Amazon SageMaker AI, Amazon Bedrock Marketplace | Vertex AI Model Garden | Azure ML Foundation Models |
| Open Source | Amazon SageMaker AI, Amazon Bedrock Marketplace | Vertex AI Model Garden | Azure ML Hugging Face | |
| Vector Database | Amazon Kendra, Amazon OpenSearch Service, and Amazon RDS for PostgreSQL with pgvector | Cloud SQL (pgvector) | Azure Cosmos DB, Azure Cache | |
| Model Deployment & Inference | Amazon SageMaker AI & Amazon Bedrock | Vertex AI | Azure ML | |
| Fine-tuning | Amazon SageMaker AI & Amazon Bedrock | Vertex AI | Azure OpenAI | |
| Low-code/No-code Development | AWS App Studio & Amazon SageMaker AI Unified Studio | Gen App Builder | Power Apps | |
| Code Completion | Amazon Q Developer | Duet AI for Google Cloud | GitHub Copilot |
Like any tech stack, Gen AI services are built by combining different components based on the use-case needs. Options exist from completely self-managed and self-hosted hardware to fully-managed AI services from cloud or third-party vendors.
AI Services General Description
For the FinOps Practitioner, many of these services fall into the categories of spending you are already tracking. Below are some of the types of cloud services that make up many Gen AI systems, and how to think about managing their costs in your FinOps practice.
Types of Cloud Services Consumed
- Infrastructure-as-a-Service (IaaS) – Core infrastructure services are provided by major public cloud vendors, such as Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and Oracle Cloud. These services typically include compute instances, storage solutions, networking, and observability tools. Additionally, specialized vendors like Nvidia target GPU-based compute needs essential for AI workloads.
- Cost Management: The primary cost drivers include compute time, storage usage, and data transfer. Common pricing models include pay-as-you-go, GPU capacity reservations, and subscription-based plans via cloud marketplaces. Understanding the pricing model associated with usage is crucial to avoid unexpected expenses and ensure effective cost tracking.
- AI platforms and managed services – Managed services simplify the operational complexity and are typically offered by cloud providers. Examples include Amazon SageMaker for ML model training, Amazon Bedrock for Gen AI, Azure’s Cognitive Services for LLM models, and Google Cloud’s fully-managed Vertex AI for building and using generative AI across many different types of user needs.
- Cost Management: Managed services often have more complex and dynamic pricing models, typically based on metrics such as the number of API calls, volume of data processed, or training duration. While these services may have higher costs compared to direct infrastructure services, they offer significant savings in time and maintenance overhead.
- Third-party software/model providers – This category includes independent vendors offering specialized AI tools, pre-trained models, and custom-built solutions tailored to specific needs.
- Cost Management: These solutions often operate under licensing agreements, subscription models, or even revenue-sharing arrangements. For effective cost management, organizations must evaluate the Total Cost of Ownership (TCO) and compare it against the potential Return on Investment (ROI) to ensure alignment with business objectives.
- API-based services – Many AI providers use a consumption-based model for pricing, which makes it easier to track costs per unit of work or consumption. With the rise of Large Language Models (LLMs) and other cutting-edge AI technologies, pricing often depends on usage metrics such as tokens generated, API calls, or processing time.
- Cost Management: Billing is typically tied to specific units of consumption, such as the number of tokens processed or API requests made. Real-time monitoring of these metrics is critical for preventing budget overruns and optimizing resource utilization. The complexity of underlying costs, driven by evolving SKUs and resource-level pricing dynamics, requires diligent tracking and analysis.
- Hybrid/Multi-cloud/DePIN/On-premises server/AI PC – While these deployment models introduce unique challenges and opportunities, they are outside the scope of this paper, but will be considered in future versions.
Gen AI Service User Personas
FinOps practices support a variety of Personas, including Engineering, Finance, Leadership, and Procurement. Oftentimes, additional stakeholders throughout an organization use Gen AI services. Understanding these user personas is crucial for developing tailored cost management strategies that align with their specific needs and responsibilities.
Because AI services are relatively new and constantly evolving — and because some of these personas may not have previous experience working with the FinOps team, or being accountable for monitoring cost and usage — additional time from the FinOps team may be required to support them.
For Gen AI Systems, your FinOps team may encounter some of the following personas:
- Data Scientists: Develop and fine-tune models, requiring access to substantial compute resources for training, testing, and evaluation.
- Data Engineers: Prepare and manage data pipelines, ensuring data is clean, organized, and accessible for AI model training.
- Software Engineers (Automation Engineer, Prompt Engineer): Integrate AI solutions into applications, often using APIs and building automation around AI workflows.
- Business Analysts: Leverage AI-derived insights to inform decisions, design data structures, and ensure data interchange for dashboards and reports.
- DevOps Engineers: Manage infrastructure, ensure efficient resource allocation, and maintain system performance for owned/managed infrastructure.
- Product Managers: Define requirements for AI features and monitor their performance and value-add to the product.
- Leadership: Set organizational goals for AI adoption, approve budgets, and define success criteria for AI initiatives.
- End Users: Consume AI-enriched outputs, often through office productivity tools, SaaS platforms, or dashboards with predictive and anomaly detection capabilities.
Types of Pricing Models that Might Be Used
A wide variety of pricing models are available for Gen AI systems. Some of these are very similar to cloud service pricing. Some are more similar to SaaS pricing.
| Paradigm | Usage Model | Cost Model | Considerations | Examples |
| On-Demand / Pay-As-You-Go | Resources provisioned as needed | Charges based on actual usage |
|
|
| Reserved Instances & Committed Use Discounts | Long-term usage commitment | Discounted rates for commitments |
|
|
| Provisioned Capacity | Long-term usage commitment | Upfront purchase of a fixed block of capacity. |
|
|
| Spot Instances / Batch Pricing | Batch or Bursty
Test/Scaling Utilize spare capacity |
Reduced rates, subject to availability |
|
|
| Subscription-Based | Fixed access to services | Recurring fees, often monthly or annually |
|
|
| Tiered Pricing | Usage-based with volume discounts | Costs vary based on usage brackets |
|
|
| Preview, Free, or Trial/Limited Use Freemium Models | Trial or Preview Period Discounts & Basic services free, premium features paid. Typically combined with other usage models | No cost for basic use, charges for advanced features or higher usage. (Watch for cost increases after preview phase ends or GA is live.) |
|
|
Measuring AI’s Business Impact
Despite widespread acknowledgment of AI’s potential, many organizations face challenges in translating its capabilities into concrete business benefits. This sentiment is echoed by numerous FinOps members and cloud/AI service collaborators; Many express enthusiasm for AI but remain uncertain about how to assess its real-world effectiveness and substantiate continued investment.
As AI transitions from experimental stages to widespread implementation, demonstrating a clear return on investment (ROI) becomes paramount. To assist organizations in maximizing the potential of this technology, a framework has been developed, focusing on six strategic priorities that empower leaders to effectively utilize AI and quantify its impact.
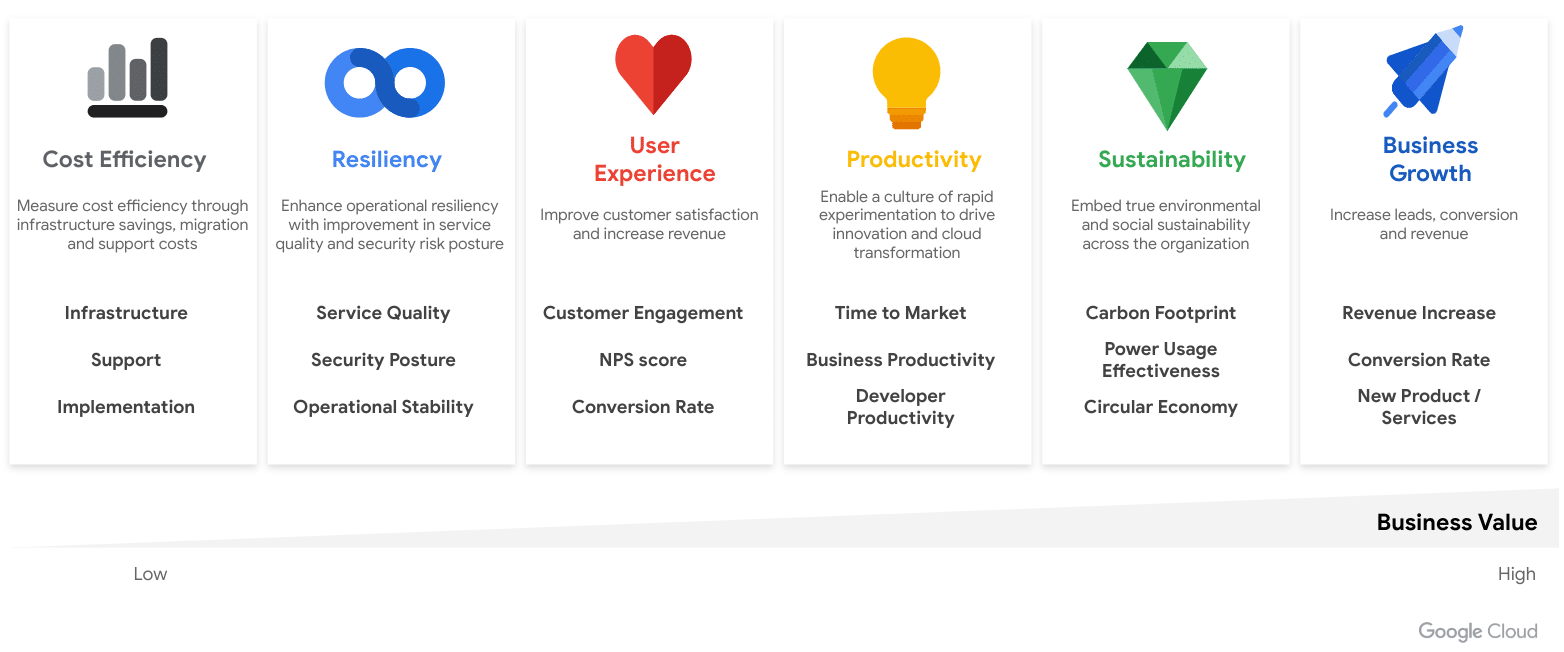
To effectively capture the business value of AI, it’s essential to establish a clear framework for measurement and analysis. This begins with aligning your AI initiatives with your overarching business goals and prioritizing the capabilities that will drive the most significant impact across this framework’s six key value pillars: cost efficiency, resilience, user experience, productivity, sustainability, and business growth.
To fully grasp the return on investment (ROI) of AI, it’s crucial to look beyond simple cost savings and consider a broader range of business value drivers and KPIs. These include enhancing operational resilience for improved service quality and security, elevating user experiences to drive customer satisfaction and revenue, boosting productivity through faster innovation and time-to-market, promoting sustainability through optimized resource consumption, and ultimately, fueling business growth by increasing leads, conversions, and new product/service development. By analyzing and measuring the impact across these six pillars, organizations can gain a more comprehensive and accurate understanding of AI’s true value.
Managing the impact of AI services
Effectively managing AI model costs requires a careful assessment of the specific needs and constraints of each application. It’s crucial to avoid using the most complex and expensive models for every task, as this often leads to unnecessary costs.
Instead, the focus should be on selecting the most suitable model for each specific context and purpose. This involves considering factors such as the required level of accuracy, data availability, computational resources, and the overall business impact.
By carefully matching the model to the needs of the application, organizations can optimize AI investments, achieve desired outcomes, and avoid incurring unnecessary expenses.
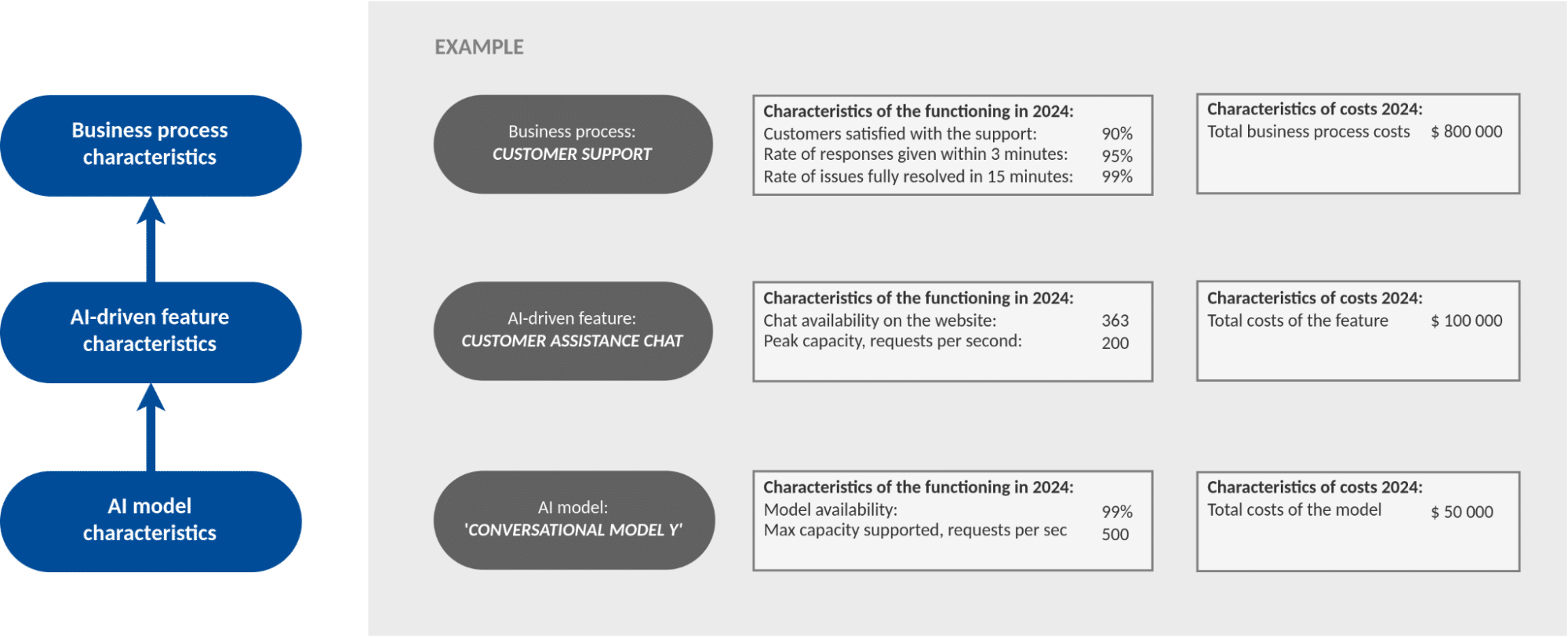
Then a decomposition of both costs and output characteristics for business is formed, as shown in the figure:
Imagine building a tower.
- A weak foundation can’t support many floors.
- If the floors aren’t strong, you can’t build a tall tower.
Similarly, in AI:
- If the data (the foundation) is poor, the AI model (the floors) won’t be accurate.
- If the model is too complex for what you need, it’s like building a skyscraper when all you need is a small house.
You need to find the right balance. A too-small model won’t work well, and a too-big model is wasteful.
Best Practices for Performing FinOps on Gen AI Services
Getting Started / Enablement
1. Educate and Train: Start by educating your team on FinOps and Generative AI concepts. The concept presented the AI costs first paper and second paper along with the “Basics of Cloud AI Costs” picture can be used as a basis. These resources help establish a high-level understanding of AI’s role within the architecture and the types of cloud resources associated with its use. Gradually progress to explaining the specific cost behaviors for different deployment types and cost paradigms. For example, understanding the cost implications of training large language models (LLMs) like GPT-4 is essential. Leverage training resources provided by cloud vendors (AWS, Azure, Google Cloud) and industry leaders like OpenAI. Additionally, consult the FinOps Foundation website for comprehensive guides on managing AI usage costs effectively.
2. Stakeholder Engagement and Gen AI Governance Model: Engage key stakeholders, including data scientists, machine learning engineers, IT teams, procurement, finance, product managers, project, change control managers and cloud solution architects. Schedule regular meetings to discuss the budgets and cost implications of running large-scale generative models versus smaller, fine-tuned models, and explore optimization opportunities. Maintain consistent communication with stakeholders to promote awareness and efficiency in managing Gen AI costs.
3. Tooling and Platforms: Invest in tools that provide visibility into AI service usage, quality, and costs. Incorporate the principles of software observability by considering both vendor-neutral and vendor-specific recommendations.
- Cloud vendor tooling: Use tools like AWS Cost Explorer and Google Cloud’s Cost Management tools for managed AI services (e.g., AWS Bedrock). For Azure, utilize the OpenAI utilization dashboard (https://oai.azure.com/) for insights into GPT costs and utilization.
- For broader applications, consider third-party solutions such as Langfuse or Langsmith, OTEL which offer detailed analytics.
4. Baseline Costs: Establish a baseline for AI-related expenditures by analyzing past invoices and usage reports. This process helps in setting realistic cost-saving targets. For instance, calculate the monthly cost of running generative models across various projects to understand your starting point. Quantify AI workload usage and adoption in terms of quality and intended business outcomes. This approach ensures that your baseline reflects both current performance and aspirations for state-of-the-art functionality. Differentiate between commodity-level services, like basic text LLMs, and advanced engineering needs, such as human-level reasoning, as these demand different cost benchmarks.
5. Baseline AI functionality: In addition to costs, identify the baseline functionality you are looking for from your AI systems. Balance the response time, quality, accuracy, and reliability goals/requirements. Evaluate the functionality of the AI models currently in use or being considered. Use quantitative metrics whenever possible, capturing both average and peak indicators. Examples include model demand (e.g., average and peak request volumes), capacity (e.g., maximum requests per unit of time), accuracy (e.g., percentage of reliable answers, user satisfaction rates, and hallucination rates), accessibility, and performance. This evaluation provides a comprehensive view of the models’ effectiveness and supports informed decisions on optimizing costs and performance.
Organizational Best Practices and Governance
1. Cross-functional Collaboration: Gen AI Services and applications will tend to be more cross-functional, impacting more parts of your organization than typical IT systems. Foster collaboration between leadership, data science, engineering, finance, procurement, and product management to ensure a holistic approach to managing AI-related costs. Establish a shared understanding of cost drivers and trade-offs between performance, accuracy, and cost efficiency. Regular workshops or meetups can align stakeholders on priorities and decision-making processes, fostering a unified approach that prevents silos and ensures cost-management efforts are seamlessly integrated into operational workflows.
2. Governance Framework: Establish a governance framework to oversee compliance, performance benchmarks, and cost thresholds. Having well-defined ownership ensures accountability and enables proactive cost management.
- Clearly define roles and responsibilities for managing AI costs.
- Assign specific owners for tasks such as monitoring costs, forecasting budgets, and optimizing model deployments.
- Governance committees or steering groups can oversee AI strategy and cost-related decisions, fostering alignment with organizational objectives.
3. Cost Accountability: Promote a culture of cost accountability by making teams and departments aware of their AI-related expenditures. Implement a showback model to provide visibility into the costs incurred by different teams. This approach breaks down costs by resource, project, or department, enabling stakeholders to see the financial impact of their AI usage without immediately charging them (as in chargeback models). The showback model acts as a powerful awareness tool, encouraging teams to optimize usage and make cost-conscious decisions. Over time, this increased visibility often drives behavior changes, such as reducing underutilized resources or shifting to more efficient deployment models. Regularly share detailed cost reports that include insights on usage patterns, efficiency, and areas for improvement. Leverage dashboards or analytics platforms to make cost information accessible and actionable. Encourage stakeholders to actively engage with this data to identify optimization opportunities.
4. Budgeting and Forecasting: Establish mechanisms for continuous improvement by incorporating feedback loops into your FinOps processes. Regularly review cost trends, optimization efforts, and business outcomes to refine strategies. For instance, after analyzing cost spikes in previous deployments, create actionable policies to prevent similar issues in the future. Continuous improvement ensures your FinOps practices evolve alongside your AI strategy and technology.
5. Training and Awareness Programs: Provide ongoing training to GenAI stakeholders on FinOps principles and the financial implications of GenAI workloads. This education should cover cost drivers, optimization techniques, and governance framework. Equip teams with the skills to analyze and act on cost and usage data effectively. Such programs ensure that cost and usage management is a shared responsibility across the organization, rather than being confined to a specific team.
Architectural Best Practices
1. Resource Management: Optimize resource allocation using features like auto-scaling and spot instances when available. For example, use auto-scaling to adjust the number of GPU instances based on the real-time demand for your generative model’s API. Additionally, evaluate reservations for predictable, long-term deployments to secure lower rates. Effective resource management not only minimizes costs but also ensures that your AI workloads remain responsive and efficient.
2. Data Storage Optimization: Choose storage solutions tailored to your data’s access patterns and life cycle. For instance, store infrequently accessed training datasets in low-cost cold storage solutions like Amazon S3 Glacier, S3 Infrequent Access or Azure Archive. Conversely, use high-performance, low-latency storage, such as SSD-based block storage, for frequently accessed datasets. Regularly review and migrate data based on its lifecycle to avoid overpaying for unnecessary high-tier storage. Consider implementing Intelligent tiering for the automation of data tiering and lifecycle policies to optimize storage over time.
3. Model Optimization: Enhance model efficiency through techniques like model pruning, quantization, and distillation. These approaches reduce the computational requirements of AI models without significant loss of accuracy. For example, use model distillation to create smaller, faster versions of large generative models, such as GPT-4 or Claude, for deployment in production environments.
4. Serverless Architectures: When applicable, adopt serverless architectures for AI workloads to pay only for the compute resources you consume. This approach is especially effective for sporadic or unpredictable workloads, such as handling infrequent API requests or experimental deployments. For example, deploy generative text models using serverless functions (e.g., AWS Lambda, Azure Functions, or Google Cloud Functions) to process requests cost-efficiently. Use serverless solutions for user stories with low service usage, early-stage experimentation, or short-lived life cycle projects. This strategy minimizes upfront investment and operational overhead while maximizing cost-effectiveness for smaller-scale or transient workloads.
5. Inference Optimization: Optimizing inference processes is essential to balance performance and cost, especially in latency-sensitive or high-throughput AI applications. Key strategies include:
- Diversify your instance types: Select instances tailored to your workload requirements. For hardware-accelerated inference, consider AWS Inferentia or Google Cloud TPU. However, if your model is developed within the CUDA NVIDIA framework, note that:
- AWS Inferentia and Google Cloud TPU do not natively support CUDA, so transitioning requires converting your model to a compatible framework such as TensorFlow, PyTorch, or ONNX.
- For CUDA-heavy applications reliant on NVIDIA libraries, it is often more efficient to stay with NVIDIA GPUs, which are supported by both AWS and Google Cloud.
- Leverage Edge computing: For latency-critical applications, deploy AI models closer to end-users using edge computing solutions. This approach minimizes delays, improving real-time performance for tasks like chatbots or predictive analytics.
- Batching for non-real-time workloads: Use batch processing to group multiple inference requests into a single operation, significantly lowering the cost per request. Batching is suitable for non-real-time workloads, such as batch predictions or periodic data processing, where latency is less critical.
- Use frameworks like GGUF, ONNX, OpenVINO and TensorRT to optimize inference performance across various hardware platforms. These frameworks ensure efficient resource utilization while maintaining model quality.
Usage Best Practices
While architectural best practices focus on optimizing the infrastructure for AI deployments and cost optimization strategies target planning and forecasting costs, usage best practices are more about managing AI consumption in real time. The goal is to monitor, control, and improve usage to ensure efficiency, avoid waste, and align resources with actual business needs.
1. Monitor usage patterns
It is important to regularly monitor how AI resources are used to detect inefficiencies or resources that remain idle. AI workloads, especially GPU-based tasks, can sometimes have unpredictable usage, leading to underutilization. For example:
- If GPU instances are not used during specific hours (e.g., off-peak periods), they should be turned off or repurposed to other workloads. A tag can help identify those instances and automate the shut down.
- If inference demand spikes at specific times, adjust your autoscaling policies to meet this demand while avoiding overprovisioning.
Tools to use: Cloud-native monitoring tools (AWS CloudWatch, Google Cloud Monitoring, or Azure Monitor) or third-party options like Langsmith can provide detailed visibility into AI usage.
2. Tagging
Implementing a good tagging strategy is essential to organize and track resources according to projects, teams, or specific AI workloads. While tagging is often used for cost allocation, here it brings visibility to how resources are being consumed. For example:
- Tag resources that are used for model training separately from those used for model inference.
- Use environment-specific tags (e.g., for a Tag ‘Environment’, with values: “development,” “testing,” “production”) to identify where consumption and costs are higher.
- Other examples in the table below:
| Tag Key (Tag ID) | Tag Value |
| Project | AI_Model_Training |
| Project | Generative_Text_Inference |
| Project | Customer_Chatbot |
| Environment | Development |
| Environment | Testing |
| Environment | Production |
| Workload | Model_Training |
| Workload | Model_Inference |
| Workload | Batch_Inference |
| Team | Data_Science |
| Team | DevOps |
| Team | ML_Engineering |
| CostCenter | AI_Research |
| CostCenter | Marketing_AI |
| CostCenter | Product_AI |
| UsageType | GPU_Training |
| UsageType | API_Inference |
| UsageType | Data_Preprocessing |
| Purpose | Experimentation |
| Purpose | RealTime_Inference |
| Purpose | Batch_Processing |
| Criticality | High / Medium / Low |
| ShutdownEligible | True / False |
A robust tagging strategy ensures clear visibility and helps teams make usage-based decisions, such as downsizing or shutting down unused resources.
3. Rightsizing
Continuously check that your AI workloads are running on the most appropriate instance size and type. Rightsizing ensures that resources are well-aligned to what your workloads require. For example:
- Use smaller GPU instances for AI inference tasks where large, expensive GPUs are not necessary.
- Replace GPUs with CPU-based compute for experiments or lightweight models that do not need GPU acceleration.
- Analyze resource utilization metrics regularly and adapt the instance type to real usage.
This approach avoids over-provisioning and underutilization, which are common sources of inefficiency.
4. Apply usage limits, throttling, and anomaly detection
To avoid unnecessary costs and unexpected consumption spikes, implement usage limits, quotas, and throttling mechanisms while combining them with anomaly detection tools. Together, these approaches ensure that usage stays aligned with budgets and prevents runaway costs caused by unforeseen demand or misconfigurations.
- Set Usage Limits and Quotas: Define strict usage limits to control how many resources are consumed, particularly for services with API-based billing.
- For example, limit the number of API calls to Large Language Models (e.g., OpenAI GPT) to manage token consumption per team or project.
- Set quotas on GPU usage for training jobs to ensure that teams do not exceed allocated budgets.
- Throttling for Cost Control: Throttle workloads during peak business hours when cost efficiency takes priority over raw performance.
- For instance, reduce the number of requests processed by inference services to avoid overloading the system and incurring unnecessary costs.
- Apply rate-limiting to experimental or non-critical workloads to align resource consumption with defined priorities and budgets.
- Integrate Anomaly Detection: Combine usage limits with anomaly detection tools to proactively identify and address unusual consumption patterns. For example:
- Set alerts for sudden increases in GPU hours or API calls, which may indicate runaway training jobs or inefficient usage.
- Detect anomalies by comparing actual usage against historical baselines to highlight unexpected cost spikes. For example, if token consumption doubles without clear justification, investigate whether it’s caused by inefficient prompts or errors in application logic.
- Tools to use: Cloud-native tools like AWS Cost Anomaly Detection, Google Cloud Anomaly Detection, or third-party monitoring solutions can automate anomaly detection, helping you react quickly before costs escalate.
By combining usage limits, throttling, and anomaly detection, organizations can ensure that consumption remains controlled, efficient, and aligned with budgets. These strategies act as safeguards to prevent misuse while providing early visibility into unusual usage trends that could lead to overspending.
5. Optimize Token consumption for API-Based models
For models that use token-based pricing, such as GPT APIs, reducing token usage can significantly reduce costs. Use techniques like prompt engineering to optimize how prompts are sent to the API. For instance:
- Shorten input prompts while keeping them clear and meaningful to avoid wasting tokens.
- Cache frequently used API responses to reduce repetitive calls.
Tracking token consumption helps identify where optimizations are needed and ensures you are using the service efficiently.
Cost Optimization Best Practices
Effectively managing AI costs requires a strategic approach that blends traditional FinOps methods with AI-specific considerations. This section highlights key practices to optimize spending while maintaining performance and innovation.
1. Manage your commitments: Leverage reserved instances and commitment plans to achieve significant savings compared to on-demand pricing. Analyze usage patterns to make informed decisions about capacity reservations:
- GPU Capacity Reservations: Commit to GPU capacity reservations when training or inference workloads are predictable.
- Cloud Rate Optimization with Vendor Discounts: Explore AI-specific purchase commitments, such as upfront API usage discounts (e.g., OpenAI Scale Tier). Regularly review new vendor offers, as AI pricing models evolve quickly and often introduce cost-saving opportunities. For example, Azure has recently introduced Monthly PTU, when PTU was only available for a yearly commitment until December 24.
- Commitment Discounts: Analyze usage patterns to determine if reserved instances, savings plan or CUDs could offer significant savings compared to on-demand pricing. For example, commit to a one-year reservation for GPU instances if you anticipate long-term use for model training purposes. Commitment discount will offer greater flexibility by applying discounts across a broader range of instance types or services. These are particularly beneficial if you lack precise visibility into your GPU requirements or expect your workloads to evolve.
2. Optimize Data Transfer costs: Minimize data transfer expenses by placing data and compute resources in the same cloud region and leveraging content delivery networks (CDNs). For example:
- Ensure training datasets and GPU instances are located in the same region to avoid inter-region transfer fees.
- Use CDNs to optimize data delivery for latency-sensitive inference workloads.
3. Proactive cost monitoring and review: Conduct regular reviews of your billing statements to catch any anomalies or unexpected charges early. For example, set up alerts for unusually high spending on generative AI services to investigate immediately.
As the AI landscape evolves, FinOps practitioners must remain agile, adopting emerging cost-saving opportunities to ensure that AI/ML investments drive maximum value and competitive advantage.
Operational Best Practices – Engineer Persona / ML Ops
To effectively manage the lifecycle, performance, and efficiency of AI/ML models, operational best practices focus on streamlining deployment, monitoring, and continuous improvement. Some of these best practices may not be things your FinOps team performs directly, but may be elements of managing cost and usage that you can bring to collaboration with engineering and operations teams you interact with.
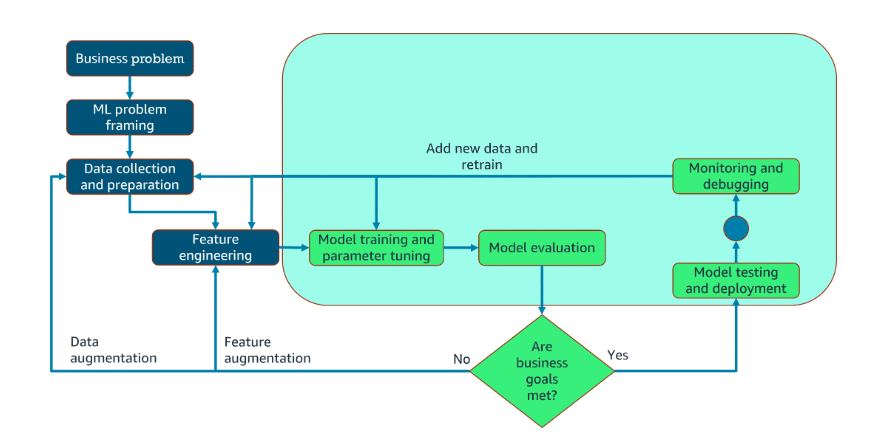
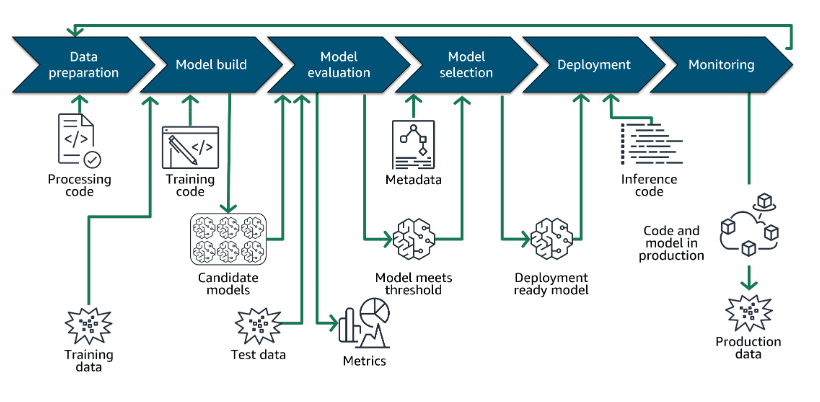
1. Continuous Integration/Continuous Deployment (CI/CD):
Implement Continuous Integration/Continuous Deployment (CI/CD) pipelines specifically designed for AI/ML workflows to automate and accelerate model delivery. Unlike traditional software CI/CD, AI workflows require additional steps such as data validation, model retraining, and performance benchmarking. For example:
- Automate the deployment of updated models using tools like Jenkins, GitLab CI, or cloud-native services (e.g., AWS SageMaker Pipelines, Azure ML).
- Include checkpoints to validate accuracy and resource consumption before pushing new models into production.
Key Advice: Automating deployment reduces operational overhead while ensuring model updates are consistent, reliable, and cost-effective.
2. Integrating Continuous Training into CI/CD:
Continuous Training (CT) is the process of automatically retraining AI models with new data to ensure they remain accurate and relevant over time. From a FinOps perspective, CT ensures cost-effective AI operations by automating the retraining process to maintain model accuracy without manual intervention. Key practices include:
- Cost-triggered retraining: Monitor data drift or performance degradation and retrain models only when necessary to avoid unnecessary compute costs. For example, use AWS Lambda or Azure Event Grid to trigger training workflows based on predefined thresholds.
- Resource optimization during training: Leverage spot instances or preemptible VMs for non-critical retraining tasks, significantly reducing compute costs.
- Selective model deployment: Evaluate retrained models against financial metrics (e.g., cost per inference, training cost efficiency) before deployment. Promote models only if performance improvements justify the additional costs.
3. Model Lifecycle Management:
Actively manage the entire lifecycle of AI models—from development to deployment, monitoring, and retirement:
- Archive or delete old, underperforming, or unused models to free up storage and computational resources.
- Regularly audit deployed models to identify those no longer needed or used for outdated use cases.
Example: Periodically review model utilization metrics and remove stale models to reduce unnecessary storage costs.
Key Advice: Treat model management as a structured process. Integrate automated lifecycle tools to ensure cost-efficiency and operational cleanliness.
4. Performance Monitoring:
AI models, especially generative ones, must be continuously monitored to ensure they meet performance goals while remaining cost-efficient. Focus on key metrics that impact both quality and resource consumption:
- Inference Latency: Track response times to ensure AI services meet user expectations.
- Resource Utilization: Monitor GPU/CPU usage to identify inefficiencies.
- Accuracy Metrics: Measure prediction accuracy and drift over time.
Use tools like Prometheus, Grafana, or cloud-native monitoring solutions (e.g., Amazon CloudWatch, Google Cloud Monitoring) to automate tracking.
Key Advice: Set up alerts for deviations in performance or efficiency (e.g., increased latency or underutilized resources) to address issues proactively.
5. Feedback Loops:
Establish clear feedback loops between operations, development, and end-users to improve model performance, efficiency, and business impact. This iterative process ensures AI models adapt to real-world usage patterns:
- Gather feedback from end-users to identify issues such as poor responses or underperformance in deployed models.
- Use operational insights to retrain or fine-tune models, focusing on both accuracy and cost optimization.
Example: For a chatbot model, monitor user satisfaction and identify high-cost prompts or responses to optimize token usage and improve cost efficiency.
Building Incrementally: Crawl, Walk, Run of managing AI Costs
Since the AI-related initiatives are relatively new and more risky compared to classic digitalization approaches, it is important to divide them into phases, each of which is characterized by a different attitude to costs. This can be described using the conventional Crawl, Walk, Run concept.
| Phase | Possible activities | Strategy in cost management | Instrumental specifics |
| Crawl |
|
– Minimal costs are invested that will cover the study of technologies, design of prototypes/MVPs, and, if necessary, their deployment in an isolated landscape (in a test circuit or in a narrow fragment of business processes in production)
– The “fail fast” strategy is applied (this means that the results of this phase should become known quickly enough and with minimal costs so that possible risks can be adjusted in a timely manner) – It is advisable to define in advance the limits of both costs and time that the company is willing to spend on achieving the results of this phase, and monitor compliance with these limits – You should not neglect the costs of the aspect that is subject to validation due to the high level of uncertainty and risks. For example, if the accuracy of the model is critical, it, as a rule, acts as an important risk factor: in this case, the costs of ensuring high quality of the model should be incurred already at this stage. – Other costs can be neglected and minimized. For example, in many cases, the service availability factor is well predictable and does not require in-depth validation. In such cases, the costs of ensuring these attributes can be neglected at the Crawl stage. |
1. Manual calculations
2. Budgets are subject to frequent revision 3. Non-financial indicators can play a dominant role for both costs and results (time spent, fact of successful confirmation of hypotheses, fact of successful readiness of artifacts/assemblies, etc.) |
| Walk |
|
– Costs associated with rolling out the solution to simple business processes (usually those use cases that were validated in the Crawl phase) with the minimum level of non-functional requirements for its daily use are reasonable.
– Compared to the previous phase, costs for deployment to production, integration, availability, and are reduced to the minimum level necessary for regular use of the AI solution in business processes – Costs for non-functional characteristics above the minimum level are subject to minimization (including costs for excessive scaling, excessive availability) – The fail fast approach is still used, especially as new features are added – Integration costs are subject to strict control – Budgets are often divided, for example, into budgets for maintaining the system’s functioning, and budgets for release costs |
1. Basic automation of cost tracking is introduced
2. Basic anomaly analysis 3. Financial metrics become more important 4. Budgets are revised less frequently |
| Run | Powering core business processes with AI | – Total costs should not be lower than a certain baseline relative to the benefits that the use of the AI model provides to the business
– Constant monitoring of costs and search for ways to optimize them will be carried out, taking into account the following – The level of non-functional requirements (NFR)at this phase becomes significantly higher. When optimizing costs, the critical priority is to avoid cutting costs that ensure that the agreed level of requirements is met. – The first to be optimized are costs that do not bring any effect at all (they do not affect the satisfaction of current requests and are not needed for future ones) – Cost reduction, which implies a reduction in the functional characteristics of the model, as well as a reduction in non-functional characteristics (even if their values are maintained above the minimal level of agreed non-functional requirements), is achieved by agreeing on architectural trade-offs based on a comparison of savings with possible negative effects – Integration costs are given higher priority and are less likely to be optimized – Budgets are divided even more deeply by components than in the Walk phase |
1. Automation of cost tracking
2. Advanced anomaly tracking 3. Integrated financial metrics are becoming increasingly important (e.g., total ROI from using an AI model) 4. Budgets are relatively constant |
KPIs and Metrics
Gen AI systems being operated by your engineering teams may use similar KPIs to traditional workloads, but Gen AI systems may also need more specific KPIs to measure how effectively we are using AI resources, or building Gen AI systems. Consider some of these KPIs, which use the terminology of AI and FinOps to capture what your organization may be trying to achieve with each Gen AI system.
1. Cost Per Inference
- What It Measures:
- The cost incurred for a single inference (i.e., when an AI model processes an input and generates an output).
- Useful for applications like chatbots, recommendation engines, or image recognition systems.
- Why It Matters:
- Tracks the operational efficiency of deployed AI models, especially for high-volume applications.
- Helps optimize resource allocation and identify cost spikes due to inefficient code or infrastructure.
- How to Measure:
- Formula: Cost Per Inference=Total Inference Costs/Number of Inference Requests
- Data Sources: Cloud billing data, logs from AI platforms (e.g., OpenAI, Vertex AI).
- If the total inference cost is $5,000 and the system processes 100,000 inference requests, the cost per inference is:$5,000/100,000 = $0.05 per request
2. Training Cost Efficiency
- What It Measures:
- The total cost to train a machine learning (ML) model divided by the model’s performance metrics (e.g., accuracy, precision).
- Why It Matters:
- Training costs for large AI models like GPT can be significant. Measuring efficiency ensures cost-effective resource usage while maintaining acceptable performance.
- How to Measure:
- Formula: Training Cost Efficiency=Training Costs/Performance Metric (e.g., Accuracy)
- Example: A 95% accurate model trained at $10,000 yields an efficiency of $105 per percentage point of accuracy.
3. Token Consumption Metrics
- What It Measures:
- The cost of token-based models (e.g., OpenAI GPT) based on input/output token usage.
- Why It Matters:
- Helps predict and control costs for LLMs, which charge per token.
- Facilitates prompt engineering to reduce token consumption without degrading output quality.
- How to Measure:
- Formula: Cost Per Token=Total Cost/Number of Tokens Used
- Tools: API usage reports, vendor dashboards.
- Example: If the total cost for inference is $2,500 and the number of tokens processed is 1,000,000, the cost per token is: $2,500/1,000,000 = $0.0025 per token
- Optimization Tip: Use caching strategies for repeated prompts and responses.
4. Resource Utilization Efficiency
- What It Measures:
- The efficiency of hardware resources like GPUs and TPUs during AI training and inference.
- Why It Matters:
- Identifies underutilized or over-provisioned resources, ensuring cost savings.
- Tracks the performance of autoscaling mechanisms.
- How to Measure:
- Formula: Resource Utilization Efficiency=Actual Resource Utilization/Provisioned Capacity
- Example: If the actual resource utilization is 800 GPU hours and the provisioned capacity is 1,000 GPU hours, the resource utilization efficiency is: 800/1,000 = 0.8 or 80%.
5. Anomaly Detection Rate
- What It Measures:
- The frequency and cost impact of anomalies in AI spending, such as sudden cost spikes or unexpected usage patterns.
- Why It Matters:
- Enables proactive identification and mitigation of runaway costs.
- How to Measure:
- Tools like AWS Cost Anomaly Detection or Google Cloud’s anomaly detection can flag outliers based on historical trends.
6. Return on Investment (ROI) or Value for AI Initiatives
- What It Measures:
- The financial or value return generated by AI initiatives relative to their cost.
- Why It Matters:
- Justifies the investment in AI services and aligns them with business outcomes.
- How to Measure:
- Formula: ROI=(Financial Benefits – Costs)/Costs×100
- Example: If the financial benefits from an AI project are $50,000 and the total costs incurred are $20,000, the ROI is: (50,000−20,000)/20,000 * 100 = 150%
7. Cost per API Call
- What It Measures:
- The average cost for each API call made to AI services.
- Why It Matters:
- Tracks the efficiency of managed AI services like AWS SageMaker or Google Vertex AI.
- How to Measure:
- Formula: Cost Per API Call=Total API Costs/Number of API Calls
- Example: If the total API costs are $1,200 and the number of API calls made is 240,000, the cost per API call is: $1,200/240,000 = $0.005 per API call
8. Time to Achieve Business Value
- What It Measures:
- The time it takes to achieve measurable business value from AI initiatives.
- “Breakeven point” of doing a function with AI vs. the cost of performing it some other way (labor)
- Why It Matters:
- Provides the awareness around the forecasted days to achieve the full business benefit vs the actual business results achieved and understanding the opportunity costs and value per month.
- Example: Forecast to get $100k/mo of business within 1 month, but it actually took 5 months and only achieved $50k/mo business benefit, 5 months was the time to business value metric to track and seek to improve.
- How to Measure:
- Formula: Time to Value (days) = Total value associated with AI service / daily cost of alternative solution
- Example: If an AI initiative starts on January 1, 2024, and the model is successfully deployed on April 1, 2024, the Time to Value is: April 1, 2024−January 1, 2024=3 months.
9. Time to First Prompt (Developer Agility)
- What It Measures:
- The engineering elapsed calendar time it takes to ready a service for first use. Or time to get from POC/Experiment into production use.
- Why It Matters:
- Mature AI patterns and tooling automations help engineers deliver more features faster, this metrics provides awareness of how fast your engineers can take ideas and turn into production user stories deliverables.
- Highlights the tradeoffs of using different methods of developing the service to get to the point where inference can occur
- Likely balanced against the need to be more accurate (quality) or less expensive (cost)
- How to Measure:
- Formula:Time to First Prompt=Deployment Date−Start Date of Initiative development
- Example: If an AI initiative starts on January 1, 2024, and the model is successfully deployed on April 1, 2024, the Time to First Prompt is: April 1, 2024−January 1, 2024=3 months
10. LM Model Choice Quality Score Alignment of Need vs Today Deviation
- What it Measures:
- How well do your prompt requirements (complexity, quality, etc.) benchmark scorematch to the available model to respond to them
- Example: A simple text block is sent for answering back with “is this text positive or negative?” sentiment only requires a MMLU score quality of 54, what is the MMLU score of the model that you are using today? What is the delta between the quality needed and the model you selected. Example MMLU rankings here for reference.
- Why it Matters:
- If you are asking high quality (expensive) models to respond to low quality (easy to answer) prompts, you are wasting resources
- How to Measure:
- What is your minimum quality MMLU score required to do that task? What model are you using today and obtain that MMLU score, then measure the cost delta for the one you chose vs is best possible today.
Regulatory and Compliance Considerations
The regulatory and compliance considerations for managing FinOps in Generative AI are critical for aligning cost management practices with legal and ethical standards. Given the rapid evolution of AI and its adoption across industries, understanding these considerations ensures financial efficiency while mitigating risks related to non-compliance.
1. Data Privacy Regulations
- Overview:
- AI services often handle sensitive data for training and inference. Regulations like GDPR (General Data Protection Regulation) in Europe, CCPA (California Consumer Privacy Act) in the U.S., and others globally impose stringent rules on data collection, processing, and storage.
- Impact on Costs:
- Ensuring compliance can require additional encryption, anonymization, masking, and monitoring tools, adding to infrastructure costs.
- Non-compliance can lead to hefty fines, which must be factored into budgeting.
- Tradeoff between privacy, quality and costs is especially interesting in GenAI space: as the models are blackboxes and PII data directly affects the quality of output, the solutions in this space are very costly and technically challenging
- Key Considerations for FinOps Practitioners:
- Assess data residency requirements to avoid cross-border data transfer penalties.
- Use cloud provider tools like AWS Artifact, Azure Purview, or Google Cloud DLP for compliance monitoring.
- Implement tagging to track resources that process sensitive data.
2. Intellectual Property (IP) and Licensing
- Overview:
Generative AI models may utilize pre-trained models or datasets, some of which come with licensing restrictions or costs. - Impact on Costs:
- Licensing fees for proprietary datasets or third-party pre-trained models can be significant.
- Misuse of copyrighted data or models can lead to legal liabilities and unanticipated expenses.
- Key Considerations for FinOps Practitioners:
- Track licensing terms and associated costs in FinOps dashboards.
- Monitor model usage to ensure adherence to licensing agreements.
- Engage with legal teams to review contracts for third-party AI services.
3. AI Bias and Ethical Compliance
- Overview:
Many jurisdictions are introducing regulations to address AI bias, fairness, and ethical use, requiring audits and governance frameworks for AI systems. - Impact on Costs:
- Auditing and mitigating bias may require retraining or additional resources, driving up costs.
- Compliance may necessitate the adoption of third-party tools for bias detection.
- Key Considerations for FinOps Practitioners:
- Include costs for periodic AI bias audits in budgeting.
- Partner with engineering teams to build explainable AI models that align with regulations.
- Use tools like IBM AI Fairness 360 to evaluate and mitigate model bias.
4. Sector-Specific Regulations
- Overview:
Industries such as healthcare, finance, and government are subject to sector-specific regulations (e.g., HIPAA for healthcare, FINRA for finance) that govern the use of AI systems. - Impact on Costs:
- Compliance requirements may mandate specific encryption levels, storage practices, or audit trails, increasing operational expenses.
- AI systems must often undergo certification processes, which can be costly and time-intensive.
- Key Considerations for FinOps Practitioners:
- Collaborate with compliance teams to map AI workloads to regulatory requirements.
- Implement region-specific configurations to adhere to local laws (e.g., using AWS GovCloud for U.S. government workloads).
- Budget for certifications or audits needed for compliance.
5. Data Retention Policies
- Overview:
Regulations may require retaining training and inference data for specific periods for auditing purposes. - Impact on Costs:
- Long-term storage costs can add up, especially for large datasets.
- Efficient data archiving solutions are necessary to balance compliance and cost.
- Key Considerations for FinOps Practitioners:
- Use cost-effective cold storage options (e.g., AWS Glacier, Google Archive Storage) for archived data.
- Tag datasets with retention policies to enable automated cost tracking.
- Periodically review stored data to ensure unnecessary datasets are not retained.
6. Environmental Regulations
- Overview:
AI workloads, especially training large models, consume significant energy. Some regions mandate carbon footprint reporting or energy efficiency standards for data centers. - Impact on Costs:
- Investments in energy-efficient hardware or renewable energy credits may increase costs but help achieve compliance.
- Tracking carbon emissions may require specialized tools.
- Key Considerations for FinOps Practitioners:
- Leverage carbon reports like those from the native cloud providers and/or third-party solutions.
- Factor in carbon offset costs as part of total AI project expenses.
- Optimize workloads to minimize unnecessary energy consumption.
- Run your workloads in a region with the least carbon-intensive energy mix (check https://app.electricitymaps.com/)
7. Emerging AI-Specific Regulations
- Overview:
Governments are introducing AI-specific regulations like the EU AI Act, which classifies AI systems based on risk and mandates corresponding compliance measures. - Impact on Costs:
- Higher risk categories (e.g., healthcare AI) may incur stricter compliance requirements, increasing costs.
- Frequent updates to regulatory frameworks require continuous monitoring and adaptation.
- Key Considerations for FinOps Practitioners:
- Monitor developments in AI regulations across key markets.
- Budget for compliance with emerging laws, including risk assessment and model documentation.
AI Scope Mapping to Framework
For a better understanding of the changes that the use of AI brings to FinOps practices, it is important to consider which Capabilities are highly differentiated when managing AI costs.
Capabilities Impacted:
| Capability | Common to non-AI and AI technologies | Different for AI technologies |
| Data Ingestion |
|
|
| Allocation |
|
|
| Reporting & Analytics |
|
|
| Anomaly Management |
|
|
| Planning & Estimating |
|
|
| Forecasting |
|
|
| Budgeting |
|
|
| Benchmarking |
|
|
| Unit Economics |
|
|
| Rate Optimization |
|
|
| Workload Optimization |
|
|
| Licensing & SaaS |
|
|
| Architecting for Cloud |
|
|
| Cloud Sustainability |
|
|
| FinOps Practice Operations |
|
|
| FinOps Education & Enablement |
|
|
| Cloud Policy & Governance |
|
|
| FinOps Tools & Services |
|
|
| IT Security |
|
|
Acknowledgments
We’d like to thank the following people for their help on this asset:

Brent Eubanks
Wayfair
James Barney
MetLife
Eric Lam
Google
Max Audet
COVEO
Joshua Collier
Superhuman fka Grammarly
Ermanno Attardo
Trilogy
Jean Latiere
Sanofi
Borja Martinez
NTT Data
Ilia Semenov
Stealth
Janine Pickard-Green
MagicOrange
Haritza Zubillaga
Roche
Rahul Kalva
Wells Fargo
JJ Sharma
KPMG
Andrew Qu
Everest Systems
Thiago Mozart
RealCloud
Bhaskar Bhowmik
Accenture
Dilli B
Munich Re
Andy Paneof
KT
Adam Richter
Amazon Web Services
Karl Hayberg
EYWe’d also like to thank our supporters and the FinOps Foundation staff for their help: Vas Markanastasakis, Rob Martin, Andrew Nhem, and Samantha White.
