Cost Estimation of AI Workloads
Table of Contents
- Prerequisites
- FinOps Personas Capabilities Alignment
- Cloud AI Deployments and Pricing Models
- Business Summary for AI Cost Planning
- AI Costing Methods, Approaches, and Examples
- Third Party Vendor Closed System Cost Estimators
- Third Party Vendor Open System Cost Estimators
- DIY Cloud Provider AI-Specific SKUs and Services Cost Estimators
- Outcomes and Indicators of Success
- Related FinOps Resources and Framework Capabilities
- Acknowledgements
This paper contains examples, experiences, and approaches of planning and estimating cloud costs for AI services; through various phases of workload development, pilot, to full production adoption. This resource includes multiple perspectives on how a FinOps practitioner may provide guidance and advisory to enterprise-wide AI forecasts and AI cost estimation processes among business leaders, finance, product teams, and engineers.
This content is best suited for:
- FinOps Practitioners involved in planning, analyzing or managing cost of applications, promotional credits for AI, or enterprise-wide shared services which include AI workloads
- Infrastructure and Application Engineers looking for example tools, forms, or approaches to help accurately estimate and plan for AI systems costs
- Financial and Business leaders who want to understand different cost drivers and learn how to leverage example forecasting methods
Executive Summary
As artificial intelligence (AI) continues to revolutionize industries and drive innovation, organizations are faced with the critical challenge of effectively planning and estimating the costs associated with deploying AI solutions. This paper serves as a comprehensive guide, illuminating the intricate financial considerations that accompany various AI deployment models. By delving into the nuances of third-party vendor commercial closed-source services, third-party hosted open-source models, and do-it-yourself approaches on public cloud providers’ AI-centric services and systems, these learnings equip readers with the knowledge necessary to make informed decisions. Moreover, it underscores the paramount importance of aligning AI investments with tangible business value, emphasizing the intricate interplay between cost, accuracy, and performance – the triumvirate that must be harmonized when dealing with AI workloads.
Prerequisites
This paper contains beginner to advanced level topics and approaches, where readers should have some introductory background knowledge into text based AI large language model (LLM) services; and available deployment methods in use or planned by their enterprise today. The report is a follow on series from How to Forecast AI Services Costs in Cloud (finops.org). Please review this content as a prerequisite to reading this paper.
FinOps Personas Capabilities Alignment
Planning and estimating AI workloads can be complex, and involves many different Personas within an organization. This section provides an overview of the roles of these Personas.
As a Senior Leader, I will estimate AI services at a service and cloud provider level ensuring a comprehensive overview of cloud-wide spend. By accessing key workload-specific use cases, I aim to understand the scalability of costs and make informed decisions that highlight the business value derived from new AI spend.
As a Financial/FP&A lead, I will estimate AI services at a service and cloud provider rollup level ensuring a comprehensive overview of cloud-wide spend, and its allocation across departments or teams to achieve a highly accurate forecast-versus-actuals variance per month and plan ahead for possible magnitude of spend growth.
As a FinOps Lead, I will offer AI cost planning advice, that includes high-level planning checklists, identification of risk drivers, spend controls, and forecasting tools alongside best practices. At the individual AI workload level, I will utilize cost planning and code-level tools to enhance cost awareness, establish accountability, and foster effective communication between engineering teams and senior leadership. This will ensure AI spend aligns with our strategic objectives and that contractual capacity commitments are fully leveraged.
As an Engineer, I will build cost estimates to enhance forecasting accuracy and maintain awareness of actual costs. I will leverage AI services specific API tooling, example code to understand the tradeoffs between deployment options, engineering choices, new AI core model/retrieval or prompts features, and will assess the quality vs. performance vs. cost trade-offs associated with new AI model features and versions. This will enable me to provide accurate cloud spend cost estimates to Finance.
As a Legal Advisor, I will ensure that our AI investments and practices adhere to existing laws, regulations, and ethical standards, mitigating legal risks associated with AI deployment and usage. By closely collaborating with the FinOps team, I will provide strategic legal guidance on contracts with AI service and cloud providers, focusing on terms that affect cost, scalability, and data privacy. Additionally, I will monitor changes in AI-related legal frameworks and advise on best practices for intellectual property management, ensuring our AI initiatives are both compliant and strategically aligned with our long-term business objectives.
As a Data Scientist,I will optimize AI models for cost-efficiency without compromising their accuracy or performance. By employing techniques such as model pruning, quantization, and efficient data management, I aim to reduce computational and storage costs. I will collaborate closely with engineers and FinOps leads to align model development and deployment strategies with budgetary constraints, ensuring that our AI initiatives deliver value in the most cost-effective manner.
As a Procurement Specialist, I will negotiate and manage contracts with AI service providers and cloud platforms to secure the best possible terms and pricing. By understanding the specific needs and usage patterns of our AI projects, I will aim to leverage economies of scale, understanding pricing trends, secure discounts, and ensure that contract terms align with our financial and operational objectives.
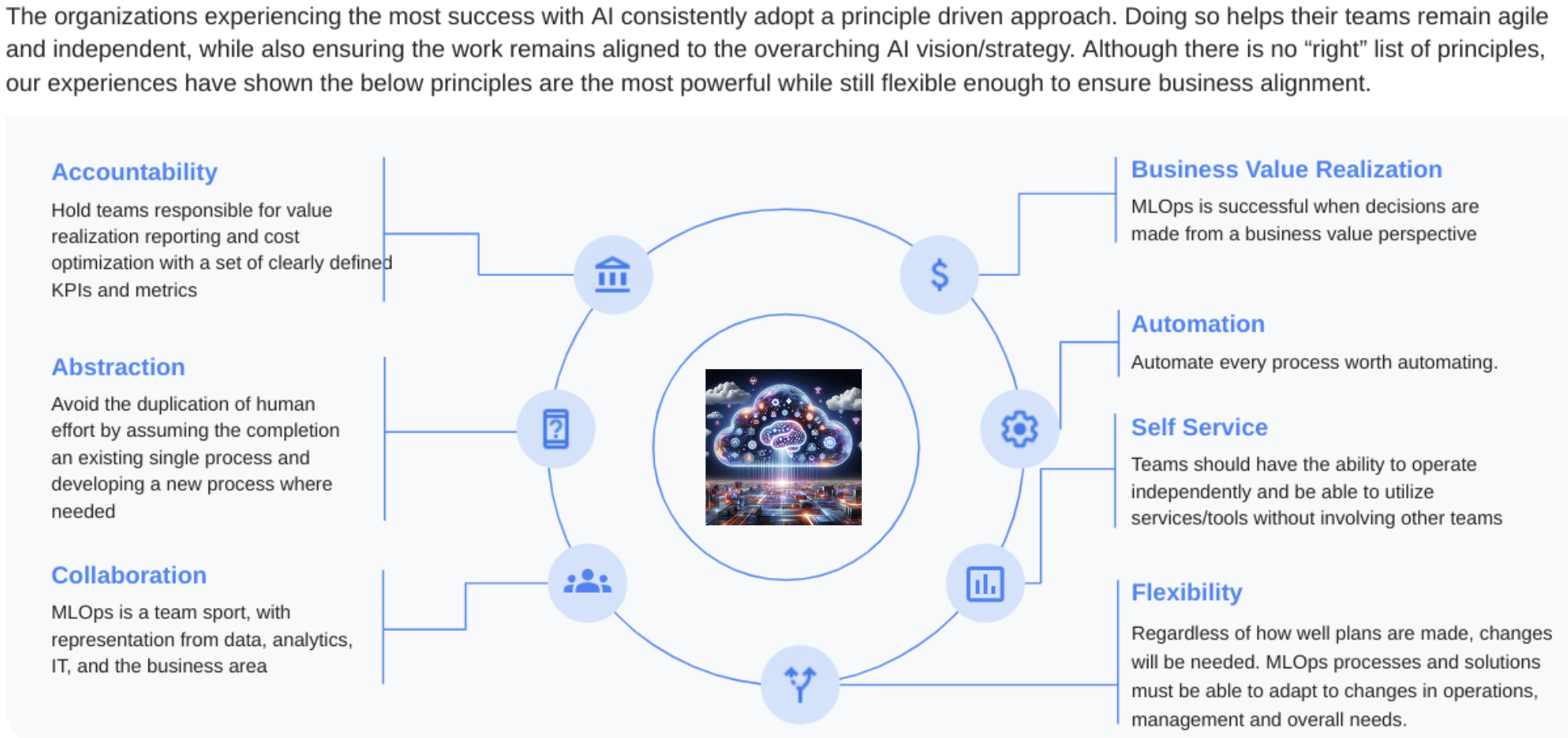
Google FinOps for AI / Courtesy of Eric Lam, Head of FinOps at Google Cloud
Cloud AI Deployments and Pricing Models
Organizations that are self-hosting models on private data centers, or treating AI as general workloads on the Cloud, may use traditional FinOps techniques and operations. These will still apply and many FinOps assets will include support for general cost estimation, forecasting, planning, and shared cost showback capabilities.
Below are key concepts to understand using the three common deployment models utilized by enterprises, includes a business summary, and explores the specific costing strategies for modern AI workloads.
- Third-Party Vendor Commercial Closed Source Services
- Examples: Text chatbots like Chat-GPT, Image Generation (like DALL-E, Adobe Firefly, etc), Speech Recognition services, and Fraud Detection solutions offered by companies like OpenAI, Google, and Microsoft.
- Pros: Rapid deployment with minimal setup. High-quality, reliable models. Robust customer support.
- Cons: Limited customization. Feature enhancements and timing is not predictable, all customers have similar features/bugs/biases, and depend on the provider to fix holistically. Costs and pricing risks due to proprietary technology. Privacy and bias concerns.
- Third-Party Hosted Open Source Models
- Examples: NLP for Sentiment Analysis, Predictive Maintenance solutions, and Autonomous Vehicle AI systems hosted on platforms like Anyscale, Replicate, Groq, or Hugging Face.
- Pros: Greater control and flexibility. Compliance with privacy and security standards that are niche or company specific to prompt, model weights, fine tune, or embeddings requirements and additional SecOps controls. Community support. No software or vendor costs and likely seen as more cost-effective than closed-source services with heavy competition driving prices down for inference serving.
- Cons: Requires higher technical expertise of folks that are already in short supply and costly. May have privacy and security default standards may not be the same from smaller/newer providers vs the hyper cloud providers. Longer time to results and iterating new ideas and new end to end solutions. Less streamlined support. Quality, guardrails,observability, and performance responsibilities lie with the user.
- Cost Drivers:
- Training Costs: While open-source models can be more cost-effective, training them for specific tasks can be resource-intensive. Training costs have gone through some improvements and still contribute to a sizable engineering cost that may range from 5-15% of the total cost of a model throughout its full lifecycle.
- Production inference and Serving client requests: The primary computing, database, storage, monitoring, and network layer costs.
- Customization and Maintenance: These models offer flexibility but require ongoing maintenance and customization, which can add to the total cost of ownership.
- DIY on Cloud Providers AI Centric Services/Systems
- Examples: Application text chatbots, code copilots, or chat with documents from mix of datasources, Self-Hosted Machine Learning Models, Recommendation Systems, and specialized applications like Medical Image Interpretation running on AWS Sagemaker, GCP Vertex AI, or Azure AI.
- Pros: Full control over models and data. Customizable cost management. Integration with broader cloud ecosystems. Easier to integrate into existing application estates, infrastructure platforms, security, roles/permissions, and operations tooling.
- Cons: Significant expertise is required where labor is short supply and costly or to leverage professional services from vendors. Longer development and deployment times, including debugging and checking quality, accuracy, and performance.
- Cost Drivers:
- Training costs: While open-source models can be more cost-effective, training them for specific tasks can be resource-intensive. Training costs have gone through some improvements and still contribute to a sizable engineering cost that may range from 5-15% of the total cost of a model throughout its full lifecycle.
- Infrastructure Costs: Significant expenses associated with the computational resources (CPUs/GPUs) required for training and inference.
- Operational Costs: Including data storage, network usage, and the labor costs associated with developing, training, and maintaining models.
- Scalability: While DIY approaches offer control, scaling these solutions to meet demand can increase costs and may require new capacity commitments with vendors at large scale needs.
Business Summary for AI Cost Planning
Before delving further, it is crucial to clarify that the responsibility for the quality of an AI product, process, or workload lies with the product managers, architects, and workload engineers. Merely measuring the consumption of AI tokens does not reflect the actual tasks performed or the value delivered to customers.
For instance, using an AI service for numerous tasks that is significantly cheaper than a top-quality GenAI model may result in delivering no tangible value to end-users. In contrast, a higher quality and more expensive solution may be capable of performing advanced technical tasks that are unattainable with a cheaper alternative. To ascertain the true quality and business value, conducting cost-versus-quality, accuracy, and performance validation tasks is imperative to ensure that the AI solutions align with the intended purpose or value proposition.
The knowledge and processes shared from the working group contributors are meant to be used to drive the conversations which include the need to address fundamental questions across the various stakeholders:
- “How can you determine if an existing model meets my requirements?”, and,
- “When faced with two existing models, how do I choose between them?”
Cost, accuracy, performance are all key functional requirements with thresholds to be clarified as a model that is very low cost but not accurate, or a model that is very low cost but not performant enough will not be used.
FinOps practitioners should devise a comprehensive strategy encompassing both a financial cloud-wide rollup AI cost planning approach and a tailored method for individual engineers and workloads. Establishing a robust AI cloud cost forecasting and planning framework is essential for effectively managing overall AI-specific services expenditure, and optimizing resource allocation rules for transparently showcasing these costs as direct or shared services to tenant users.
A high-level rollup spend forecast and plan offer Finance and Senior Leaders a holistic view of their organization’s incremental AI services costs, facilitating strategic decision-making and budget allocation at a macro level. This enables the identification of cost trends, drivers, value analysis for transitioning into full-scale production, and identification of potential cost-saving opportunities throughout the entire cloud infrastructure.
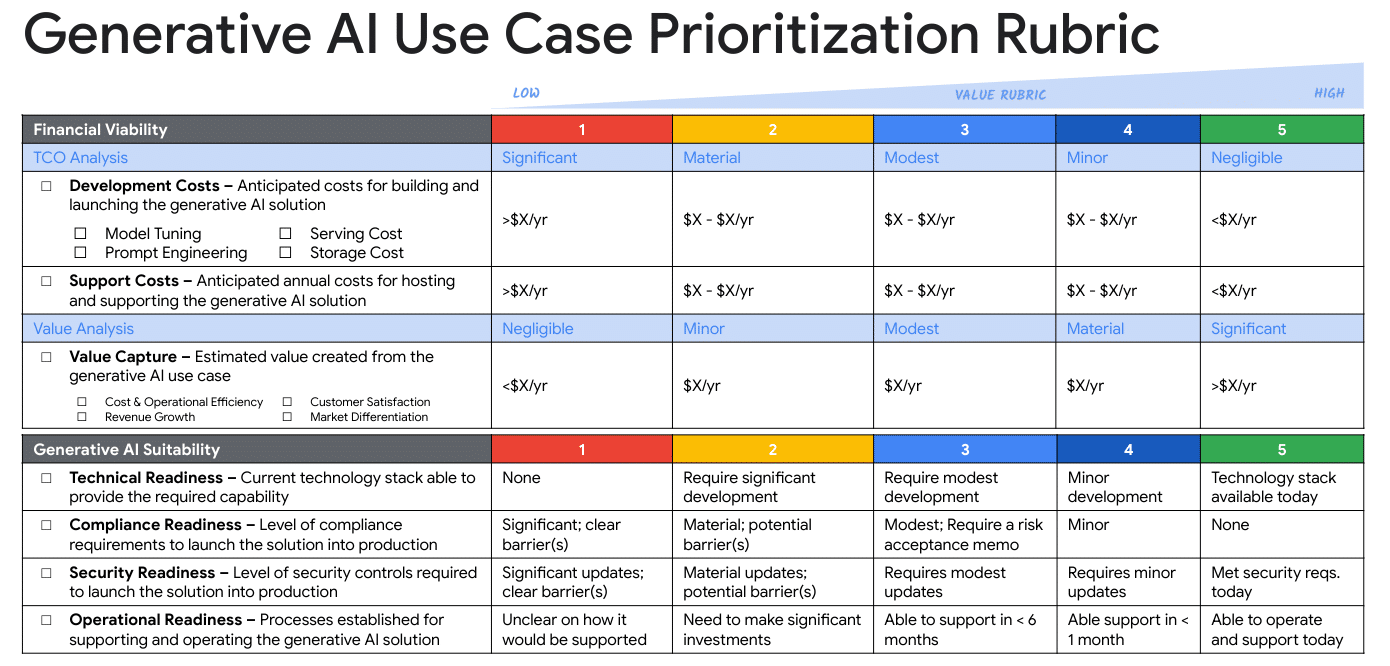
Courtesy of Google Cloud – FinOps Best Practices
The following illustration is an example of a decision tree to drive the right investments with the right cost plans to provide business value, labor productivity, or accelerate feature timelines. This example explains the advisory approach by which the investment into that solution should be delivered. Therefore, the opportunity is to discuss the best approach for the need where a simple spreadsheet add-on will be purchased, a private and secure customized solution would be partnered, and a niche high-value customized workload should be built by your team.
The generative artificial intelligence article published on Arthur D. Little is a good primer on this topic and is the source of the below image.
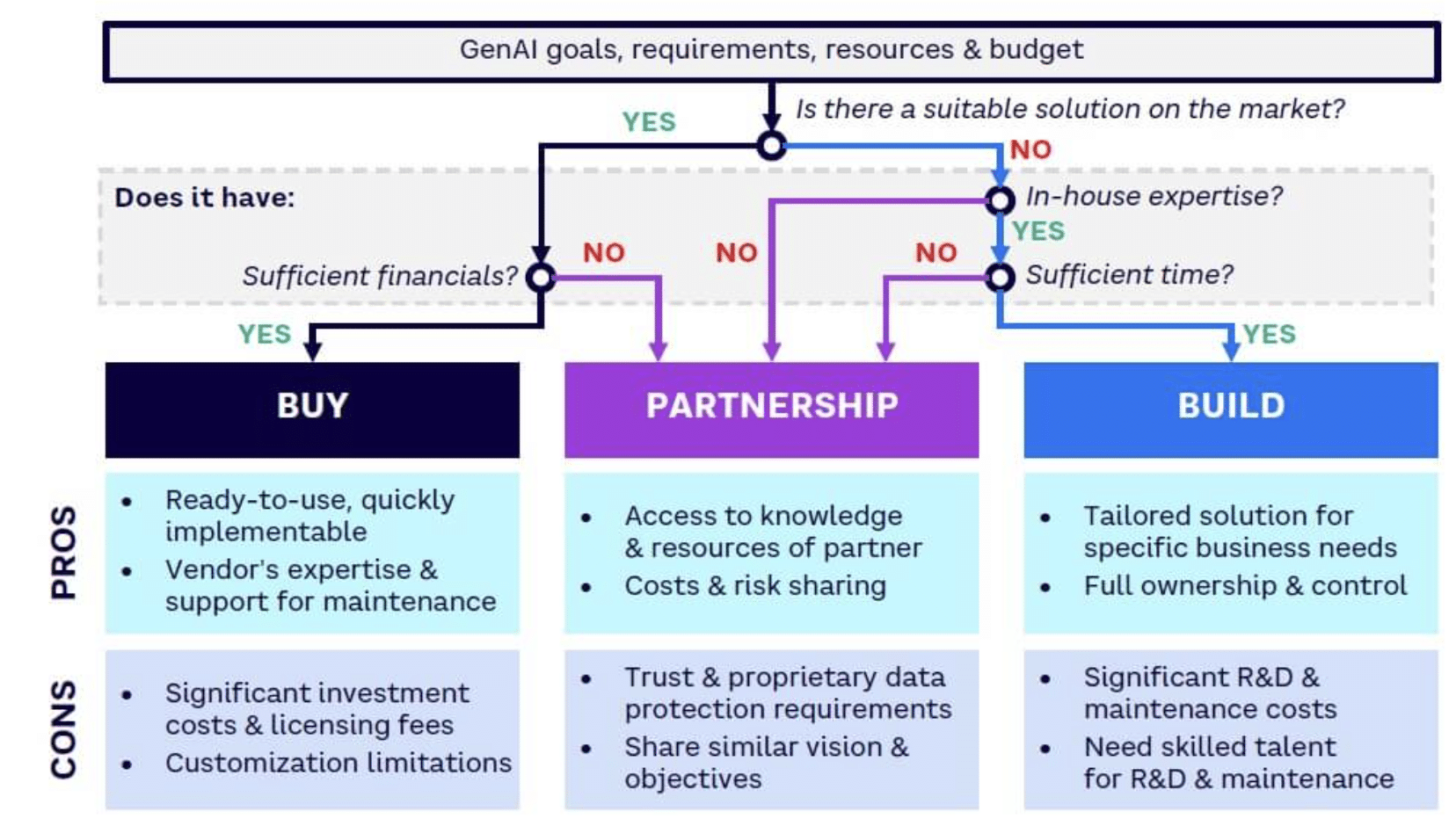
In addition to the high-level rollup AI spend forecast, it is essential for companies to implement a separate AI cost forecasting and planning tool and approach for individual engineer workloads. Ideally, this tool will provide engineers with a user interface, or simple form or spreadsheet or enable a code and CI/CD level function to perform this cost awareness or cost comparison process programmatically. This granular level of analysis at scale and with automation enables engineers to understand the specific cost implications of each architectural decision and help test the newest model with the latest pricing discounts from the different options that are constantly improving within the cloud providers offerings.
By doing so, companies can align individual workload costs with business objectives, track resource utilization, and ensure that engineering teams operate within budgetary constraints. Accountability of deploying an AI workload is the responsibility of the workload owner to forecast and plan properly and FinOps is supporting this with rates, estimators, and showback reports and any other optimizations best practices to help foster business value and align the capacity, contractual and committed usage plans.
The topics and examples to follow are provided to ensure that the business persona is able to understand the methods, approaches and the typical advisory topics to understand and be able to bring into your organization and start the collaboration on these topics. The examples cover a basic and advanced AI cost forecasting example in order to share the experience and wisdom of the working group participants and industry current state of best practices.
FinOps is the balance of financial management and the developers’ engineering choices to understand and interchange data and ideas to achieve maximum business value together. Amazon Web Services (AWS) provides a simple yet powerful business investment illustrative matrix to help the company decide where to put the limited people and money into the annual plan when there are too many great ideas.
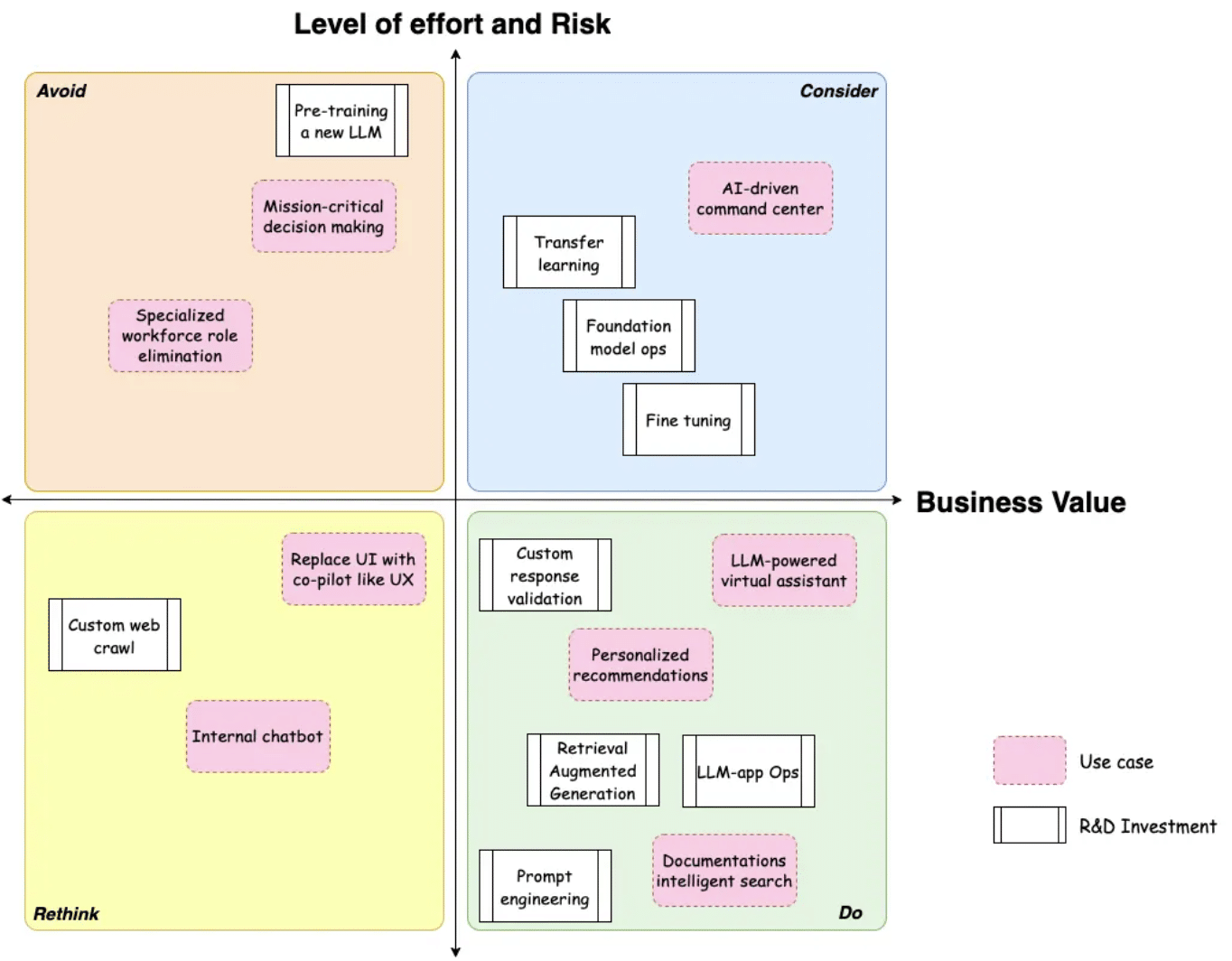
Courtesy: AWS Gen AI Project Prioritization article
The AI costing and forecasting approaches in use by your business today still apply, layering in these AI specific approaches to ensure quality and accuracy are important to balance with cost.
AI Costing Methods, Approaches, and Examples
Let’s start with a quick refresh from the original AI paper where we understand the cost drivers for each deployment method being leveraged today. These are the key quantities and engineering decisions that should be understood when the FinOps team is guiding a frugal architecture, or the business is looking to compare different deployment methods and would like to estimate the similar solution costs from different engineering choices and tradeoffs.
In the rapidly changing AI field, accurate cost forecasting is crucial for FinOps teams.
Key factors include:
- Understanding cost drivers and AI pricing trends
- Mastering capacity planning
- Adapting to frequent innovations that impact deployment usage/costs
- Aligning financial outlays with business value
- Driving efficiency within cloud AI service operations as part of broader program
Here are some examples for FinOps practitioners to drive these discussions for the business to enable data driven value decisions as the AI technology is incorporated into the operations and new products are launched.
Cost Drivers for Various AI Systems
When considering the implementation of AI in the cloud, it’s important to understand the major cost drivers. Here are some key cost factors to keep in mind:
- Computing Resources: AI workloads often require significant computational power, which can drive up costs. This includes the cost of running and maintaining the servers, storage, and networking infrastructure needed to support AI applications.
- Data Storage and Transfer: AI models often require large amounts of data for training and inference. Storing and transferring this data can be costly, particularly if you’re dealing with high-bandwidth requirements or transferring data across long distances.
- AI Model Training: Training AI models can be a time-consuming and computationally intensive process. The cost of training a model can vary widely depending on the complexity of the model, the amount of data used for training, and the computational resources required.
- AI Model Serving: Once an AI model is trained, deploying it in a production environment can also be costly. This includes the cost of serving the model, managing versioning and scaling, and monitoring performance.
- AI Model Monitoring and Maintenance: AI models require ongoing monitoring and maintenance to ensure they continue to perform accurately and efficiently. This includes tasks like retraining the model, updating data inputs, and addressing any performance issues.
- Cloud Provider Fees: Cloud providers like AWS, Azure, and Google Cloud charge fees for using their infrastructure and services. These fees can vary depending on the specific services and resources used, as well as the volume and duration of usage.
To keep costs under control, it’s important to carefully plan and manage your AI cloud implementation. This may involve optimizing your infrastructure and workloads, using cost-effective cloud services and pricing models, and implementing best practices for data management and model training.
To effectively manage FinOps spend and make financially aware engineering choices, it’s crucial for businesses to understand the cost drivers of different deployment options of AI services, from simple departmental chatbots to complex, globally scaled services. This requires a comprehensive understanding of the various approaches and their associated costs, as well as the ability to accurately forecast and optimize expenses. By taking a financially informed and cost-conscious approach to AI development and deployment, businesses can ensure that their AI investments align with their strategic objectives and deliver long-term value.
Third Party Vendor Closed System Cost Estimators
Introduction to the Cost Estimator Model
Many cost estimators are available and this is only an example to convey the concept of what can be built or code reused for this type of application consumption and quantity-driven cost estimation.
Key Inputs and Cost Calculation Methodologies
This Gen-AI Cost Estimator Repo on GitHub is home to an AI cost estimator tool. AI cost estimators require a few key inputs:
- Current vendor pricing (contractual term discounts, promotional credits/offsets), platform model types related to the current vendor
- Select the items that are approved and ready for use by the business, keep the items for models and unit rate pricing updated
- Sample prompt and scenario areas to help the user experience understand what is typical quantities or cost figures to go in each cell for self-service
- Enable the custom calculations for different levels of choices, duration, and usage.
- Only applicable for shared capacity type
AI cost calculators that serve as a good example is this OpenAI estimator pricing structure for third party. Closed Source examples include OpenAI and Cohere.
The major cloud providers (AWS, Azure, GCP) offer a mix of closed-source and open-source AI options. The choice depends on your engineering team’s overall AI strategy and tooling approach. Even the available “model garden” illustrates pricing variability due to advancements in capabilities and competition from both closed and open-source AI approaches.
The following waterfall chart shows a sample AI costs breakdown report to help manage spend. Blue represents development costs, and yellow and red are the highly variable costs for scale driven by consumption of the service. Understand that FinOps practitioners and related personas may be able to assist with capacity planning, capacity purchase agreements with the Cloud/AI providers to reduce the month over month cost variability, future spend risk, and lower unit costs by having a longer term commitment of usage.
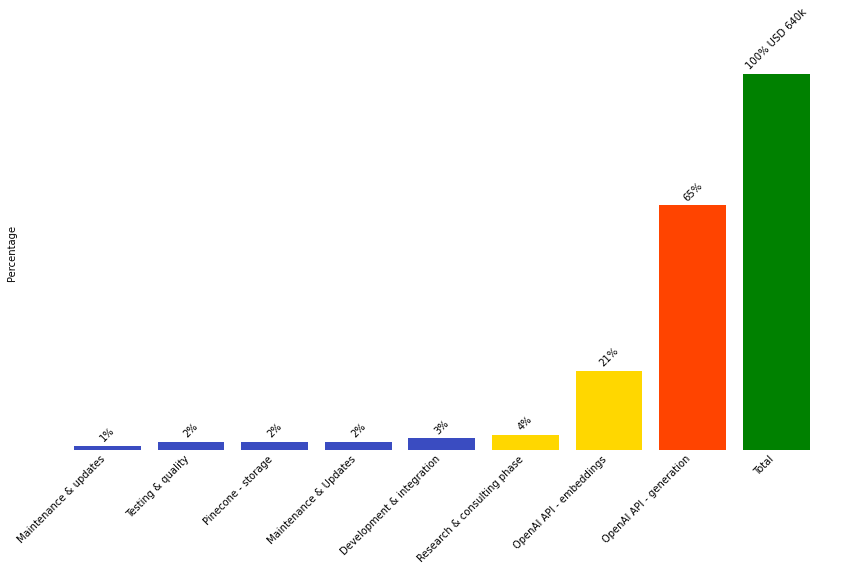
AI Cost Breakdown example
Benchmarking and Capacity Planning
Provisioned capacity is an upfront purchase of throughput for a specific model (I.E., GPT 3.5 Turbo or GPT 4 Turbo). In Azure OpenAI, the cost-per-PTU (Provisioned Throughput Unit) is the same across all models. However, a more compute-intensive model like GPT 4 will have a lower throughput per PTU than GPT 3.5.
In AWS Bedrock, PTU cost varies according to model type and commitment term. Vendors will provide a range of tokens per minute (TPM) per capacity unit expected for each model. They will generally have internal calculators that can be leveraged to help estimate usage.
Provisioned throughput can provide guaranteed availability and consistently low latency for AI workloads for significant up-front costs. With high utilization, it can also provide long-term savings over the course of a given workload. However, there is no way to dynamically scale down provisioned throughput. For example, if the majority of your customers interact with your systems during your daytime hours, the provisioned throughput will incur the same hourly rate at night with low usage as it would during the day with high usage. Due to the fixed nature of provisioned capacity, when you change from per-token billing to provisioned throughput billing, it is crucial that your cost modeling for workloads also changes.
It’s recommended to refer to the TPM range provided by the vendor to get started. However, to determine where your usage fits in the range and ensure that your capacity is performing as expected, it’s critical for the customer to perform their own benchmarking. This will enable accurate forecasting and capacity management. Benchmarking should be done periodically, especially as the average size per request changes. New services may need to be benchmarked individually if request sizes are significantly different.
Once you have a benchmark (i.e. 300k TPM per 100 PTU), plan capacity according to the expected peak usage, as it can take days to weeks to add more capacity, depending on the vendor and demand. Other capacity planning and forecasting considerations include:
- Does all or part of the services require redundancy?
- If so, the number of regions impacts your utilization target. I.e., if you have two regions, you lose redundancy at 50%+ utilization of total capacity.
- Decide on utilization metrics and thresholds to indicate if more capacity is needed.
- If usage is consistent and your target peak utilization is 50%, the purchase threshold could be at 45% peak utilization for 3 days or more. If usage is volatile, the threshold would need to be lower.
- Not all vendors allow dynamic switching or fall-back between provisioned throughput and on-demand per-token billing modes.
- Application code will need to be modified to handle throttling when usage is higher than provisioned throughput in order to meet customer needs
- Not all models from all vendors are available in all regions, especially cutting-edge models
- Depending on the use case, using older, more widely-available models might be required to ensure high availability of the AI system
To help with benchmarking, Azure provides a benchmarking tool and a capacity calculator in GitHub. To access the calculator, you need an existing OpenAI resource in Azure.
Key Lessons
Third-party closed systems generally provide two options to use their API, each requires different methods to estimate costs.
- Standard or shared capacity is much like other cloud-based resources in that you’re charged only for what you use. Rates are based on token type (input and output), model, and context size. Like other on-demand resources, availability is not guaranteed.
- Provisioned capacity is similar to other types of capacity reservations; scalability is limited or unavailable, upfront payment is commonly required, and commitment length impacts cost. Costs are based on the number of Provisioned Throughput Units (PTU) purchased. The amount of throughput per unit can vary per application, which makes benchmarking critical. However, the inability to add capacity quickly (days typically) means that cost forecasts must be based on expected peak usage for each purchased period.
- The fixed nature of provisioned capacity can lead to higher cost-per-token-used as compared to shared capacity. The decision to use provisioned capacity could be more so driven by application performance needs rather than cost efficiency improvements.
Third Party Vendor Open System Cost Estimators
Introduction to the Cost Estimator Model
Let’s take a simple approach versus a use case-specific example. This simple approach is similar to the above modeler, where we only require a few example inputs from the workload estimator to produce a cost estimate.
A simple open-source or open-model platform based cost estimator as mentioned above has some ability to be reused for this type of Application consumption quantity-driven cost estimation.
Key Inputs and Cost Calculation Methodologies
The cost estimator that is built requires a few key inputs:
- Current vendor pricing, platform model types related to the current vendor
- Select the items which are approved and ready for use by the business, keep the items for models and unit rate pricing updated
- Sample prompt and scenario areas to help the user experience understand what is typical qty’s or $ figures to go in each cell for self-service
- Enable the custom calculations for different levels of choices, duration, and usage
Benchmarking and Capacity Planning
With Generative AI experiencing massive adoption in the 100s of millions of users, the providers are struggling to keep up with infrastructure capacity. If your enterprise is looking to obtain AI services at scale, your enterprise should have a capacity plan that includes procurement terms, pricing and credits, and spend commitments in order to ensure your AI service is able to scale on your needs.
There are many different views on how FinOps and Engineers are forecasting the costs of AI workloads and the quality continues to improve to provide more choices and options to align the complexity with function and accuracy. These resources here are a small fraction of what is available and feel these are worth a review. Check out the online estimator from the illustration below and GitHub repo for reuse.
- GCP Pricing, AWS Pricing, Azure Pricing, Oracle Pricing, IBM Pricing
- Groq, Huggingface, Anyscale, Replicate, together, deepinfra
- Cost comparison across providers for a open model calculator example
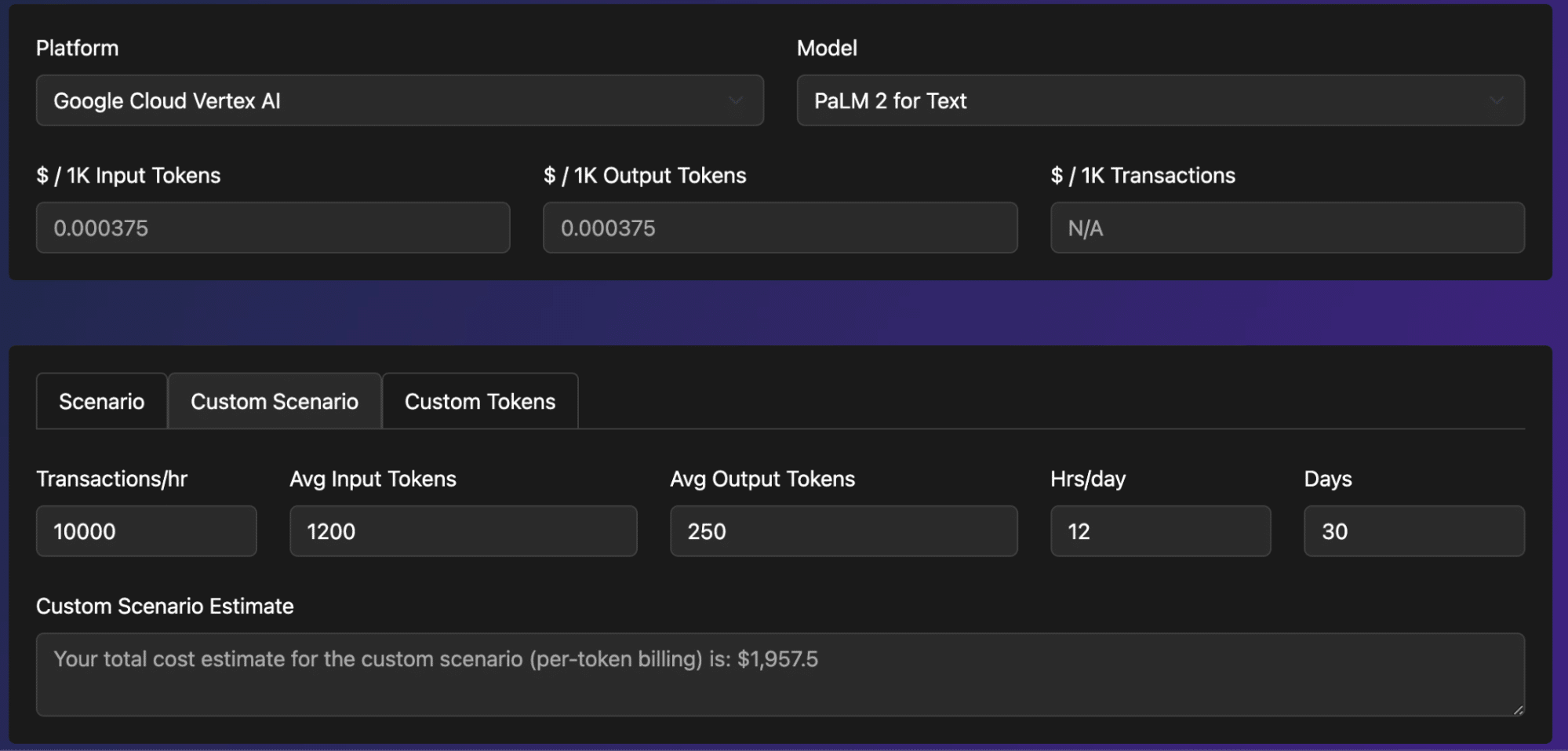
The other common approach is to refer to the Cost Drivers for Various AI Systems section in the first paper around user story or feature that is being AI amplified.
AI Cost Example:
Here is an example approach that considers many new facets that will drive costs and also allow some reuse for similar types of user stories.
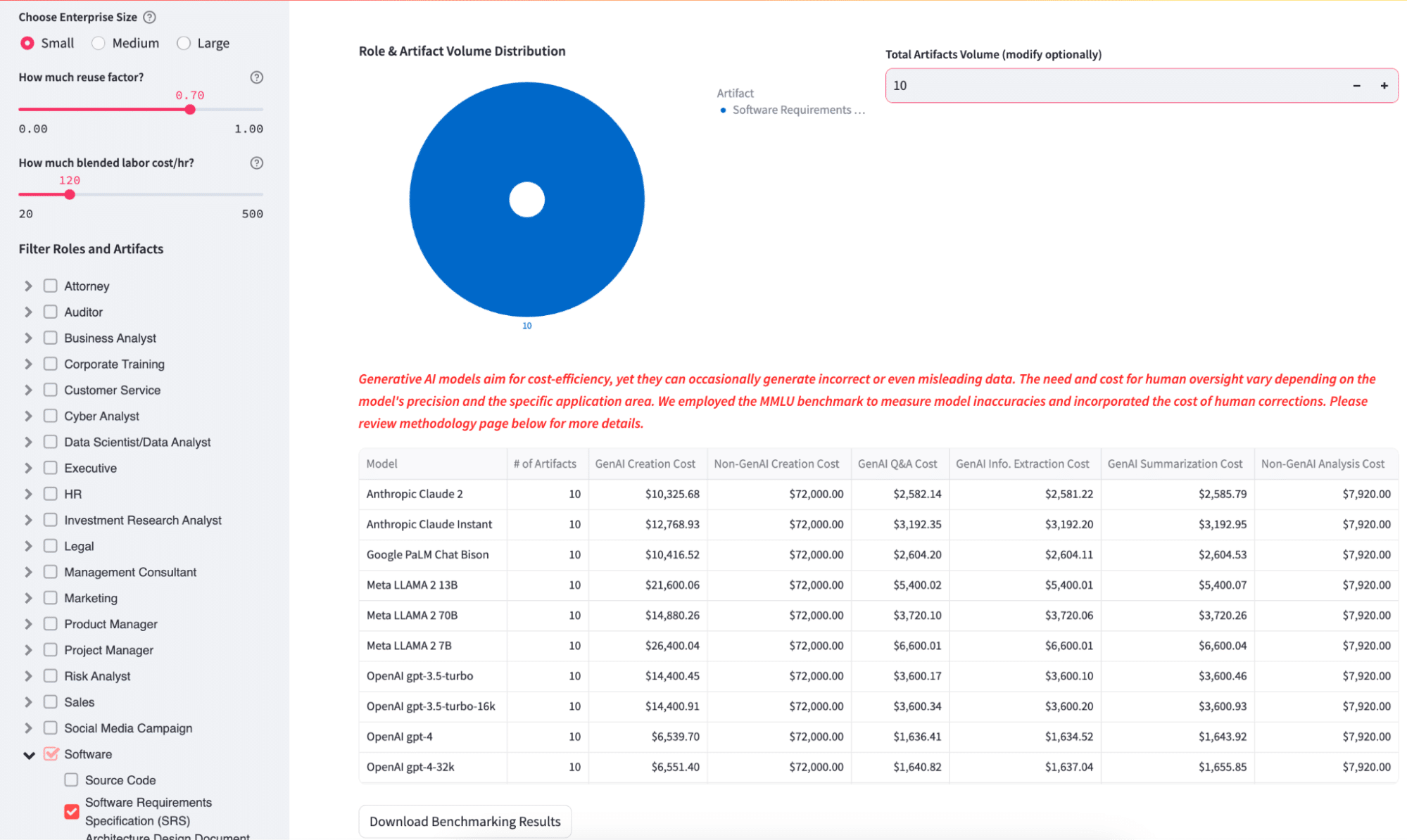
Enterprise size: Choose enterprise size that closely resembles your organization in terms of number of employees. Enterprise Generative AI Pricing Estimator app uses a proprietary method to model an enterprise, roles, artifacts usually produced by the roles and context associated with such artifacts, which then serves as input to calculate the benefit and lift from generative AI vs non-GenAI.
Reuse Factor: Reuse factor considers how much of prior art/templates of existing artifacts can be leveraged to create a new artifact. It ranges from 0 to 1, where 1 means 100% reuse, and 0 means nothing can be reused from the past.
Blended Labor Cost: Human blended labor cost in US$/hour based on your organizational profile across various roles.
Department Persona and Artifact/Software Product: Select the type of dept and the type of artifact, service, or software product being scoped.
Total Artifacts: What is the total number of artifacts that should be modeled.
Cost Estimate Produced with Columns of the different approaches to build and operate.
See the GitHub repo for this type of modeler.
Key Lessons
- Look at all the different public models that are compatible with your enterprise environment. Different platforms offer a variety of models, with varying costs.
- Use the Gen AI Cost Estimator to get an estimate of potential cost for the deployment.
- Deploying specialized smaller private models can help make a wide-scale enterprise deployment more CFO-friendly.
- See how the per-token billing costs for your scenario match up against having a dedicated LLM instance (through platforms like Hugging Face or your favorite Cloud provider).
- Remember, that deciding on a private model deployment will mean extra management overhead that wouldn’t exist compared to public model SaaS providers.
DIY Cloud Provider AI-Specific SKUs and Services Cost Estimators
Introduction to the Cost Estimator Model
We will use a specific AI workload to help walk through the different steps using a text-based AI tool for sentiment analysis. This is an example (see source) where the cost of AWS SageMaker with a sentiment analysis artifact is being estimated using multiple services from the cloud provider.
Key Inputs and Cost Calculation Methodologies
Most engineers will progress through a cost estimation or planning and awareness series of steps. The intent is to share what others have done, have an example of online tools or code calculators that help provide the awareness of cost drivers, and then compare what different engineering choices and scale of quantity of adoption will do to costs.
The items below are meant to provide a sample of what is helpful for the phase and scope of the AI workload costing being done by that persona. The intent is to share some experience as this is a rapidly evolving practice where sharing different approaches and models is best, and the FinOps practitioner can then decide which approach and level of complexity would make sense to improve cloud spend accountability and ensure decisions promote desired business outcomes.
- MVP/POC type experimentation: What is the cost difference if I know how many tokens in and out? Here are a couple examples to compare different options. Open AI centric.
- Are there any free AI tools that are available while I am learning or want to try things out? (here’s an example by GCP).
- Compare model types/versions against one another for cost and quality.
Beginner – Online comparison example
Advanced – Code example for automation or scaled use
- With LLM testing you can determine if you need GPT-4 or if you can save money and time with GPT-3.5
- You can find the minimum number of tokens you can use without sacrificing quality
- Compare different LLM providers to determine which is the best fit for your application
- Scale to a full service needs to incorporate full ai stack costs and lifecycle items.
- Costs are estimated but how to estimate value vs total spend and other AI ideas as a company wide cost estimation and planning example?
- Multi-vendor cost benchmarking – a tool like skypilot benchmark may be useful.
- Understand the initial, ongoing, and hidden costs for a true TCO of spend required


AI TCO – Hidden Costs Exist
- Cost modeling with incorporating time scaling or time variables for rates, discounts, engineering improvements by AI workload type.
Application-Centric Cost Planning Approach
The following section is meant to walk through five concept steps to understand main cost drivers for a given AI application workload, and help determine which deployment model should be used. The cost unit rates contained in these sections are not kept up to date, so please focus on the different steps in example to comprehend what should be considered in a detailed engineering cost estimation process, and how you would capture these items into your cost planner. Do not assume rates described below are accurate.
Step 1. Tokens with a model and cost inputs
The following workload example is a sentiment analysis of text with a text output:
- Transactions/hour: 1,000 transactions every hour
- Average Input Tokens: Input prompts have an average of 100 words
- 1 token is about 0.75 words, around 133.33 tokens average (let’s round that up to 150 tokens on average)
- Avg Output Tokens: 36 output tokens (let’s round that up to 50)
- Hours/day: operates 12 hrs / day
- Days: compute the cost for 30 days.
The model must require the correct context window or amount of text words that can be input and output as consideration.
| Platform Model | Monthly (12hrs/day, 30 days) |
| OpenAI GPT-3.5 Turbo 16K | $90.00 |
| OpenAI GPT-4 8K | $2,700.00 |
| Amazon Bedrock Cohere Command | $117.00 |
| Amazon Bedrock Claude Instant | $187.20 |
| Amazon Bedrock Claude 2 | $1,183.32 |
Using a simple cost estimate strategy like we’ve outlined here helps you identify the large variance in cost to help decide on which platforms and models to explore for different use cases.
Advanced AI analysis serves as a good resource and the source of the below sample illustrations:
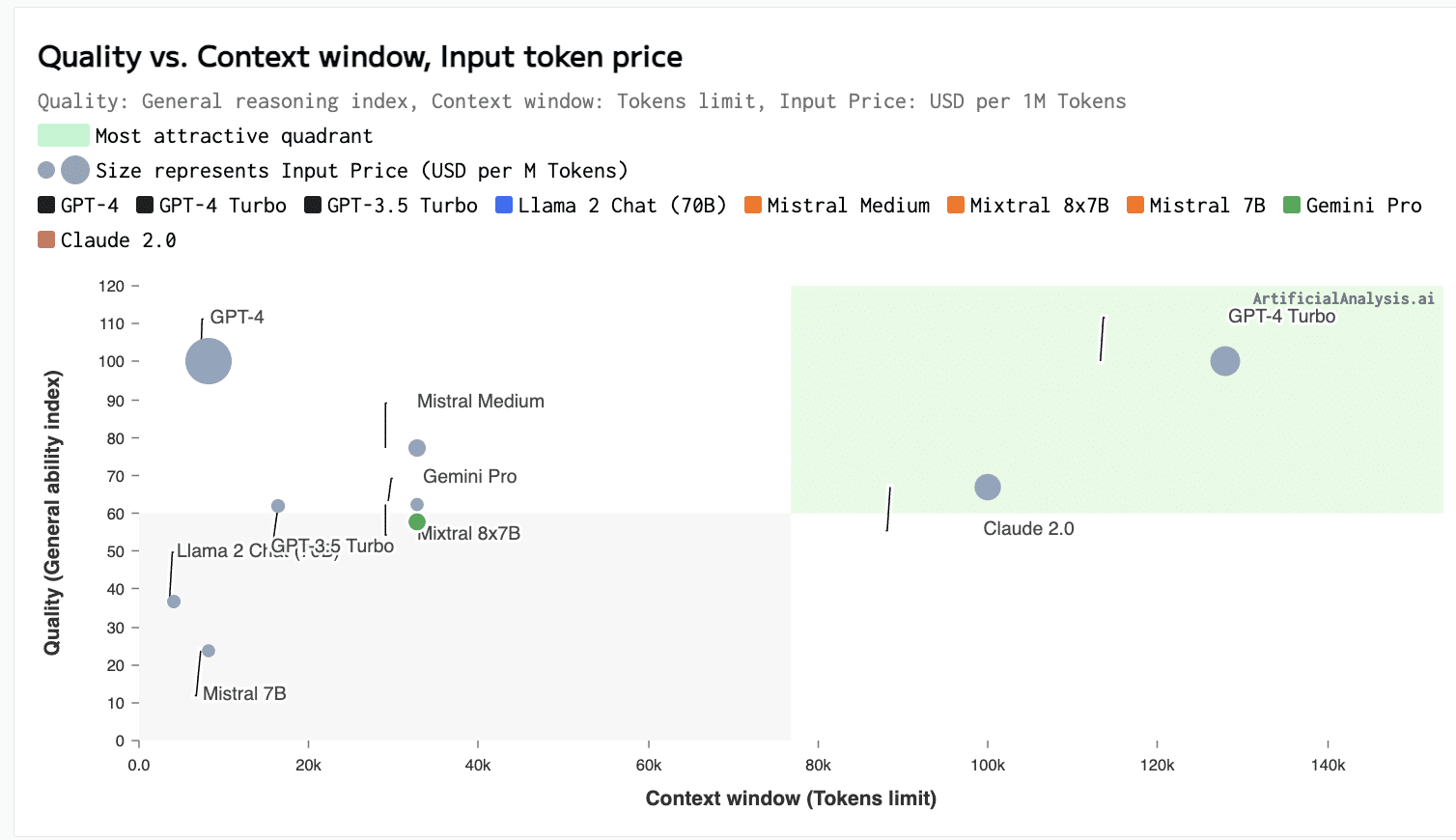
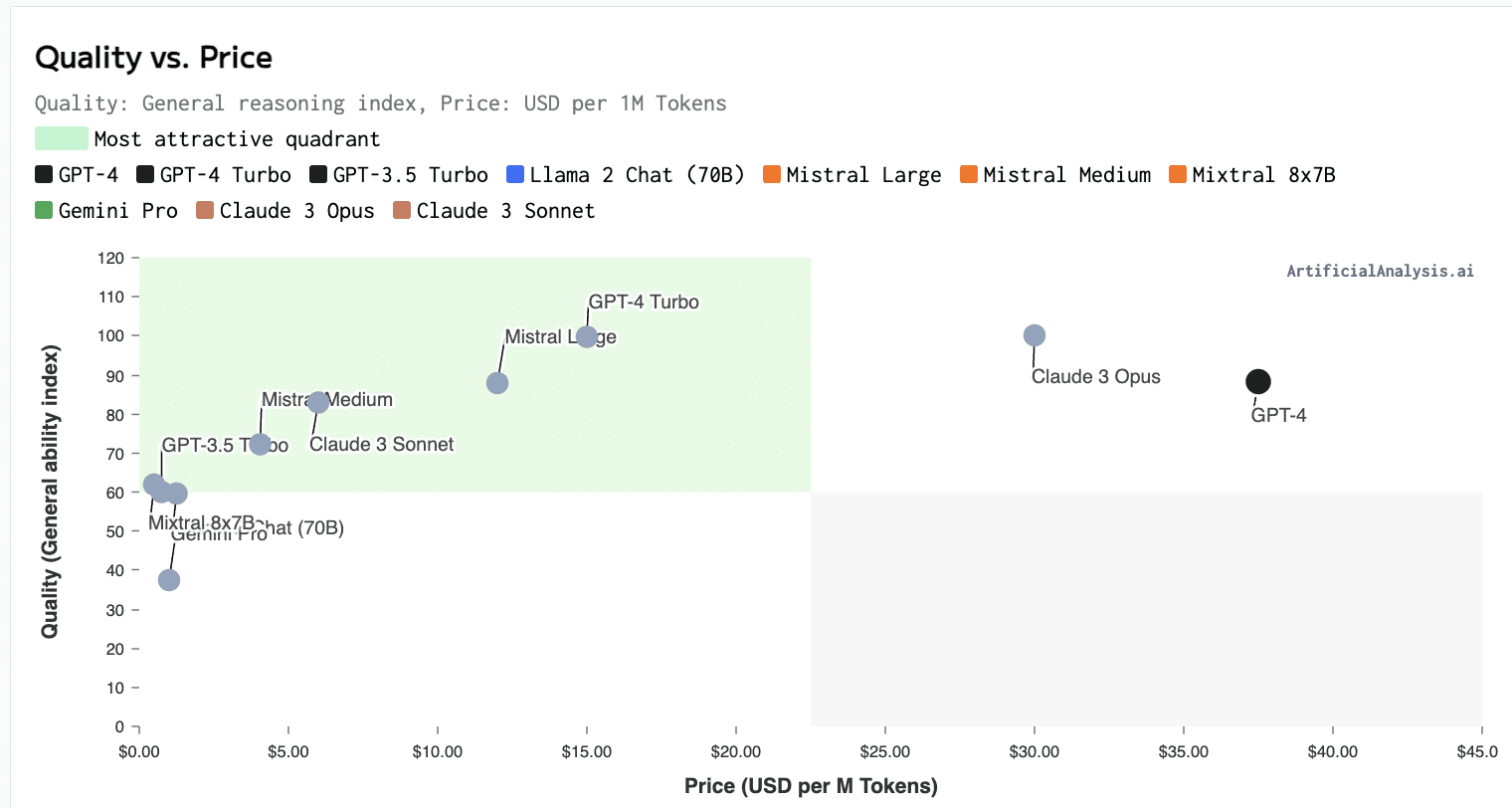
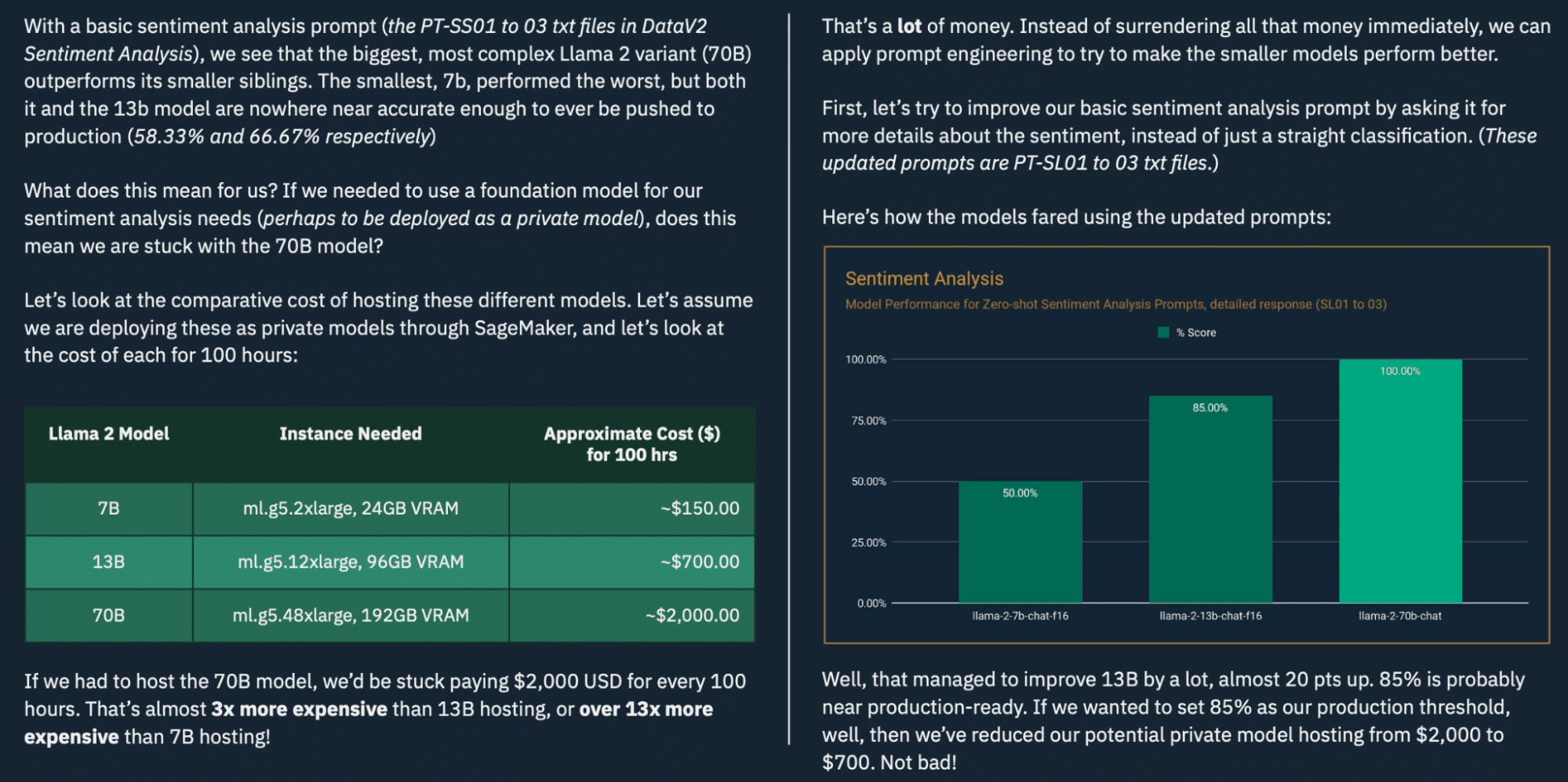
Step 2. Updated prompts
You should understand prompt engineering to test the accuracy, performance, and costs of the prompt by using a tool with comparison tests to ensure quality is known for the size and quality of the model for that given prompt. With the better prompt engineering, the preferred method was to use the few-shot learning and detailed sentiment analysis response prompt. This paper is not going into detail on AI optimization tactics in depth and should understand that tools like llmlingua can dramatically reduce the costs and should be evaluated before finalizing large workload forecasts.
- Average Input Tokens: The new prompts contain an average of > 700 words, for an estimated 1,000 input tokens on average
- Average Output Tokens: Our benchmarking experiment yielded an average of 147 output tokens (let’s round that up to 150)
| Platform Model | Monthly (12hrs/day, 30 days) |
| OpenAI GPT-3.5 Turbo 16K | $468.00 |
| OpenAI GPT-4 8K | $14,040.00 |
| Amazon Bedrock Cohere Command | $648.0 |
| Amazon Bedrock Claude Instant | $884.34 |
| Amazon Bedrock Claude 2 | $5,731.92 |
Due to the token counts much larger for the input (due to few-shot learning) and also significantly increased for the output (due to asking for more details), our costs jumped significantly.
Previously, when we prompt engineered the sentiment analysis capability using the Llama 2 models, we were only concerned with instance-hr pricing. Without caring about the amount of tokens, few-shot learning seemed like a valuable, cheaper deal, allowing us to reduce our hosting cost.
Now, in the per-token-billing world, you have to think about costs differently. The platform vendor takes care of managing the infrastructure, so that’s less management overhead for the workload owner. But now every token counts, which can and should influence our prompt engineering and deployment approach.
Step 3. When to use dedicated instances vs per token billing
Based on the Llama 2 7B, we only need the 24GB VRAM (GPU memory) instances in either Hugging Face or SageMaker. That’s approximately $500.00 for our expected usage.
With Llama 2 13B, we would need either the 80GB instance from Hugging Face or the 96GB instance from SageMaker. That’s approximately $2,500.00, or a very large cost jump. The full Llama 2 70B model will need either the 160GB or 192GB instances, and the costs either $4,700.00 for the slightly smaller Hugging Face instance, or $7,000.00 for the slightly bigger SageMaker instance.
Let’s combine this instance-hour cost table with our previous few-shot learning per-token cost table, and sort them by cost.
| Platform Model | Monthly (12hrs/day, 30 days) |
| OpenAI GPT-3.5 Turbo 16K | $468.00 |
| Hugging Face (24GB) Llama 2 7B | $468.00 |
| SageMaker (24GB) Llama 2 7B | $547.20 |
| Amazon Bedrock Cohere Command | $648.0 |
| Amazon Bedrock Claude Instant | $884.34 |
| Hugging Face (80GB) Llama 2 13B | $2,340.00 |
| SageMaker (96GB) Llama 2 13B | $2,552.40 |
| Hugging Face (160B) Llama 2 70B | $4,680.00 |
| Amazon Bedrock Claude 2 | $5,731.92 |
| SageMaker (192GB) Llama 2 70B | $7,329.60 |
| OpenAI GPT-4 8K | $14,040.00 |
From the table we can see how costs by solution rank given our sentiment analysis scenario: Deploying a Llama 2 7B inference endpoint in either Hugging Face or SageMaker is one of our cheapest options. GPT -4 is incredibly expensive. With this amount of money, we could already maintain a small cluster of Llama 2 7B or 13B for load-balancing and high-availability, and still save several thousand dollars per month. Bedrock offers reasonable options with varying levels of cost.
Remember, that table shows results for our particular scenario. The argument for or against going with hosting your own model will vary greatly as you change the parameters of your scenario. Given more tokens used, hosting your own LLM might appear more attractive. Increasing operational hours per day but keeping total daily tokens the same (having the total transactions spread out over a 24-hr period instead of 12), per-token billing will appear more attractive.
In summary, per-token versus per-instance-hr billing results in vastly different economics. Benchmark and model your scenario for quality and instance vs token pricing models. Use an estimator like the Generative AI Cost Estimator to help you quantify your costs of the various options with quality and performance context. Consider running models locally during development and experimentation, whenever feasible.
Step 4. Quantization
Quantization in the context of AI and large language models (LLMs) like GPT (Generative Pretrained Transformer) is a technique used to reduce the model’s size and computational requirements, making it faster and less resource-intensive to run, especially on devices with limited processing power. This is achieved by reducing the precision of the numerical values that represent the model’s parameters (weights and biases). For example, instead of using 32-bit floating-point numbers, the model might use 8-bit integers.
Quantization has two major benefits – it’s cheaper to run them (only need smaller instances with less GPU memory or CPU based) and will inference faster (which improves the user experience by reducing time to answer).
Example with Llama 2 13B: It has 13 billion parameters. Those parameters are mostly 16-bit floating point values (f16). Space-wise, that means 13 billion x 2 bytes (16 bits / 8 bits per byte) = 26 billion bytes, or 26GB. If you downloaded Llama 2 13B, you’ll see that the model does take up 26GB of disk space – loading that into memory therefore also needs 26GB of RAM. If we use quantization to make this smaller, say q4 (4-bit quantization), then we’d be slicing our storage (and RAM) needs by 4 (from 16-bit values to 4-bit values), so we’d lower storage and memory needs significantly.
With quantization you can easily fit 3 of this Llama 13B q4_K model into the smallest Hugging Face or SageMaker instance. Not necessarily that you want to – but to show how much capacity there is, and the amount of volume you can expect such a server can now handle, given the slimmed down 13B model. Best of all, you’ve just reduced your 13B hosting cost from ~$2,500 to just ~$500. If we apply the same treatment for Llama 2 70B, we go from ~140 GB of space, to just under 45GB! From the table above, that means our hosting costs dropped from $5.7-7.5K USD, to just ~$2.5K USD (cutting costs by more than half!).
Rerun the tests to ensure that there are no significant losses in quality of response by using quantization. At least for this sentiment analysis use case, quantization doesn’t seem to hurt quality. Therefore we can quantize our models aggressively, down to q4, and expect minimal-to-zero performance hit – at least according to our test samples.
Step 5. Fine-tuning
Fine-tuning is the process of making foundation models perform better in specific tasks. We can see that in the correctly answered items, our foundation models aren’t very compliant with any specific formatting. It’s significantly better for the few-shot ones, but still not as consistent as it could be.
This is where fine-tuning can come in. With fine-tuning, we provide additional nice, clean, sample data that is representative of the specific task we want to tune the LLM for. In the case of our sentiment analysis use case, that could be a data set containing real product reviews from our customers. We label these samples correctly (i.e., also provide the ideal sentiment analysis output for these, according to our human experts), and our fine-tuning training set then becomes a few dozen review samples coupled with their ideal answers.
Through the fine-tuning process, this new training data set is “added” to our LLM’s knowledge, so that the LLM understands better how to handle this specific task.
The technical details of fine tuning will not be covered in this paper, high level steps are listed.
Prepare and validate training data
Data Collection, Data Cleaning and Preprocessing: Ensure your data is clean, which means it should be free of irrelevant content, formatting issues, and sensitive information.
Validating Your Dataset
Train a New Fine-tuned Model: Upload training and validation data or choose from your existing files into the tuning tools for the provider and model being used.
Once you are done with the fine-tuning process, the real test of success is checking that results did indeed improve their performance for the use case we fine-tuned them for, compared to the standard (non-fine-tuned) base model.
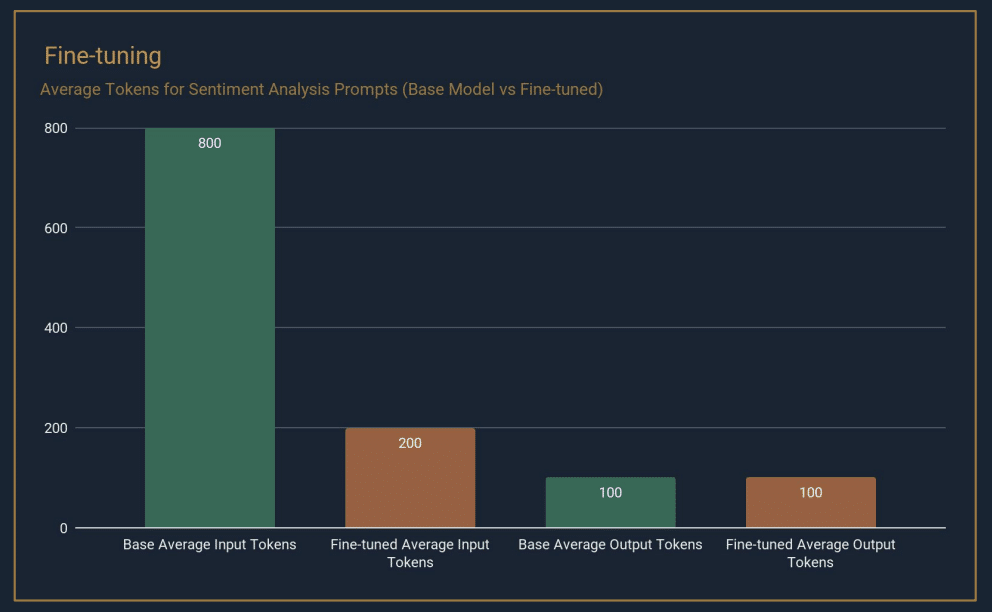
Source JV Roig
Fine-tuning gave us a huge decrease in average input tokens because our fine-tuned models don’t need few-shot learning anymore. For Llama 2, since we’re looking at it from a private model perspective, there’s not a direct effect of lowering costs since we don’t pay per token. We are saving on some VRAM and a little inference time, however, so our inference servers will be able to handle a little more volume without scaling up.
Key Lessons
- Always benchmark your fine-tuned models after the fine-tuning process to make sure the training is a success. Don’t just rely on the validation set and the training and validation loss metrics.
- Don’t forget to evaluate the cost impact as well. In this specific use case, we found that, cost-wise, we’d be better off just implementing few-shot learning on the base GPT-3.5 instead of using our own fine-tuned model due to rates increase for fine tuned. Few-shot gave us comparable performance (accuracy and compliance to output format), but for almost 20% less money than using a fine-tuned model. Fine-tuning can be very powerful, but it requires preparing data and paying for the fine-tuning process – both of which can be expensive activities. Before settling for fine-tuning as the solution to your problem, try prompt engineering first. It can be a much smaller lift.
Our Gen AI cost forecasting and examples are complete for this era of time– let’s put them all together to highlight essential cost control measures.
For initial R&D, exploratory tinkering and use case development, default to public models and per-token billing. In these phases, your LLM usage will likely be low enough that per-token billing will be far more cost-effective than paying for instances. The Gen AI Cost Estimators tools can help you shortlist the first platforms and models to test based on estimated cost. Look for free or promotional usage from your cloud providers.
Production costs
Look at all the different public models that are compatible with your enterprise environment. Different platforms offer a variety of models, with varying costs. Use the Gen AI Cost Estimator to get an estimate of potential cost for the deployment. Deploying specialized smaller private models can help make a wide-scale enterprise deployment more CFO-friendly. Use the most expensive proprietary models like GPT-4 judiciously. Don’t simply default on using the biggest and most expensive models as the backbone of your production features.
Outcomes and Indicators of Success
Effective cloud spend management and engineering leaders for AI services should clearly understand the major cost drivers when forecasting AI cloud costs for a multitude of reasons. The unpredictable nature of cloud spending, compounded by potential seasonal fluctuations in workload demands, necessitates accurate predictions to avert financial oversights. A robust framework of technology-neutral unit metrics and comparison methodologies is crucial to discern the cost variances in deploying AI workloads.
Given the rapid evolution of AI across every level of the technology stack and the notable price volatility among vendors and cloud providers, it’s vital for organizations to grasp and anticipate these changes. This foresight allows companies to proactively optimize their cloud spending forecasts and manage expenses efficiently. With global expenditure on public cloud services expected to surge, underscored by its growing necessity, mastering cloud cost management becomes imperative.
Key Benefits
- FinOps Teams will gain a methodology for AI cost planning, including a suite of pertinent tools and examples. This will support extensive AI cost estimation and planning, targeting over 90% expenditure accuracy.
- Financial and Business Leaders will become familiar with the intricacies and various strategies for planning at an enterprise level versus the analysis of individual projects. This knowledge will improve decision-making regarding technology investments for AI projects.
- Application and Platform Engineers will be informed of diverse models for cost planning. The provided approach and tools encapsulate the collective expertise on AI workload forecasting methodologies, enabling engineers to navigate through the complexities of development, staging, and production phases, along with the associated financial considerations.
Indicators of Success
- AI shared services and company wide level cloud service forecasting is within 90%+ accuracy with known cost and variance drivers.
- Workloads using the standard approaches recommended by FinOps to produce more consistently accurate spend plans for their workloads.
- Reduce or remove the bill shock that is typical with AI poor planning and reactionary tasks associated to scale up growth with unknown cost consequences.
- Understanding the cloud provider levers when scaled larger capacity needs is requiring new commitments, terms, or capacity mgmt discussions to ensure AI workloads are reliable and performant at scale.
Related FinOps Resources and Framework Capabilities
- Shared services cost forecasting and showback is a highly correlated framework capability.
- Get involved in future AI topics in the working group, including possible papers on AI workload optimization, unit metrics for AI, AI capacity management, or AI governance. Please use the slack channel #chat-finops-ai-ml for any AI topics.
Acknowledgements
We’d like to thank the following people for their work on this paper:

Brent Eubanks
Wayfair
Joshua Collier
Superhuman fka Grammarly
Ermanno Attardo
Trilogy
Alireza Abdoli
Tesla
Max Audet
COVEO
James Barney
MetLifeWe’d also like to thank our supporters: David Lambert (TAC Liaison), Sean Stevenson, and Eric Lam.