Why Architecting Databases for Cost Efficiency Matters
Summary: Database platforms represent one of the fastest-growing segments of cloud spending, making architectural decisions a critical driver of long-term cost efficiency. Learn how to incorporate cost-aware design principles when architecting cloud databases. Evaluate pricing models, usage patterns, and workload requirements early in the application lifecycle so that organizations can improve cost predictability and avoid inefficient database architectures. FinOps Practitioners can use key inputs, architectural decisions, and persona collaboration needed to build database systems that balance performance, scalability, and financial accountability.
FinOps involvement at earlier stages of the application development lifecycle can help proactively build in FinOps practices, resulting in a more cost-effective cloud infrastructure. While we’ve covered cost-efficient general VM architecture in a previous work, this paper focuses on how to architect databases with cost efficiency in mind.
Read this paper to learn how incorporating the most effective pricing and usage strategy during the application’s design phase aids in accurate upfront cost estimation and optimization as it relates to databases.
Purpose of this guide
This paper is an extension to previously published Architecting VM-based Applications for Cost Efficiency and should provide FinOps practitioners with a foundational understanding of cloud database efficiency. It covers key considerations FinOps practitioners should explore with business and technical stakeholders to plan for architecting cloud databases for cost efficiency.
NOTE: This document will not cover any data analytics (Hadoop, Spark, Databricks, Snowflake, BigQuery, EMR), managed data storage or streaming databases (S3, Redshift, Datalake, Amazon Timestream). Those services could be topics for future papers.
Looking at Database Design with Cost Efficiency in Mind
Database management systems are the largest and fastest growing segment of cloud spending (IDC). 63% of enterprises are already migrating databases to the cloud, and an additional 29% are considering migrations to cloud databases in the coming three years (IDC).
In 2022, 98% of the overall database management system (DBMS) market growth came from cloud-based database platforms and cloud database platform-as-a-service (PaaS) share reached over half (55%) of the overall market (Gartner, June 2023). The shift from procuring database licenses and infrastructure as a capital expense (CapEx) to pay-as-you-go database services as an operational expense (OpEx) enables organizations to only pay for what they use.
The dynamic nature and near infinite capacity of the cloud make cloud database usage and spending unpredictable. Even worse, inefficient database architectures can go undetected, resulting in dramatically higher cloud costs. In order to optimize resource usage and ensure cost predictability, it is essential to architect databases for cost efficiency before deploying them into production.
When architecting database workloads for the cloud, it is important to consider a number of challenges and risks that may impact total cost of ownership and business results, including:
- Licensing: Before choosing a database platform, it is important to consider the license implications, including impact on existing vendor contracts, features excluded from the license you choose, and your team’s ability to add new features, compared with open source alternatives
- Support: Database configuration, upgrades, maintenance, backup, and security patching can become mundane and toilsome taks, but can result in costly downtime and additional risks if not managed properly
- Service Level Agreements (SLAs): Managed cloud database services typically include guarantees for availability and maintenance, so be sure to review the SLAs and confirm they will meet the requirements for your current and future applications
- Performance: Common challenges include network latency, database vertical or horizontal scale limits, inefficient data storage/retrieval, suboptimal query design such as unnecessary SQL joins and table column width, wrong indexes, fragmentation, and overprovisioning resources in an attempt to speed up processing times
- Vendor lock-in: proprietary databases can help organizations reduce the time and effort required to configure, deploy, and manage cloud databases but may limit choices about features, third-party integrations, regional availability, security, scale, and cost
- Cost management: The rapid growth of cloud database spending, combined with the unpredictable nature of the cloud have led cloud database cost to become the number one concern of IT leaders
Definition of a Cloud Database
A cloud database is a database built to run in a public or hybrid cloud environment to help organize, store, and manage data within an organization. Cloud databases can be offered as a managed database-as-a-service (DBaaS) or deployed on a cloud-based virtual machine (VM) and self-managed by an in-house IT team.
Databases types, use cases and deployment models
Databases are organized collections of data that are designed to store, manage, and retrieve information efficiently. There are several types of databases, each with its own strengths and suitable use cases. Some common types of databases are:
- relational databases (RDBMS),
- NoSQL databases,
- object-oriented databases,
- time-series databases,
- in-memory databases,
- spatial databases, and
- NewSQL databases
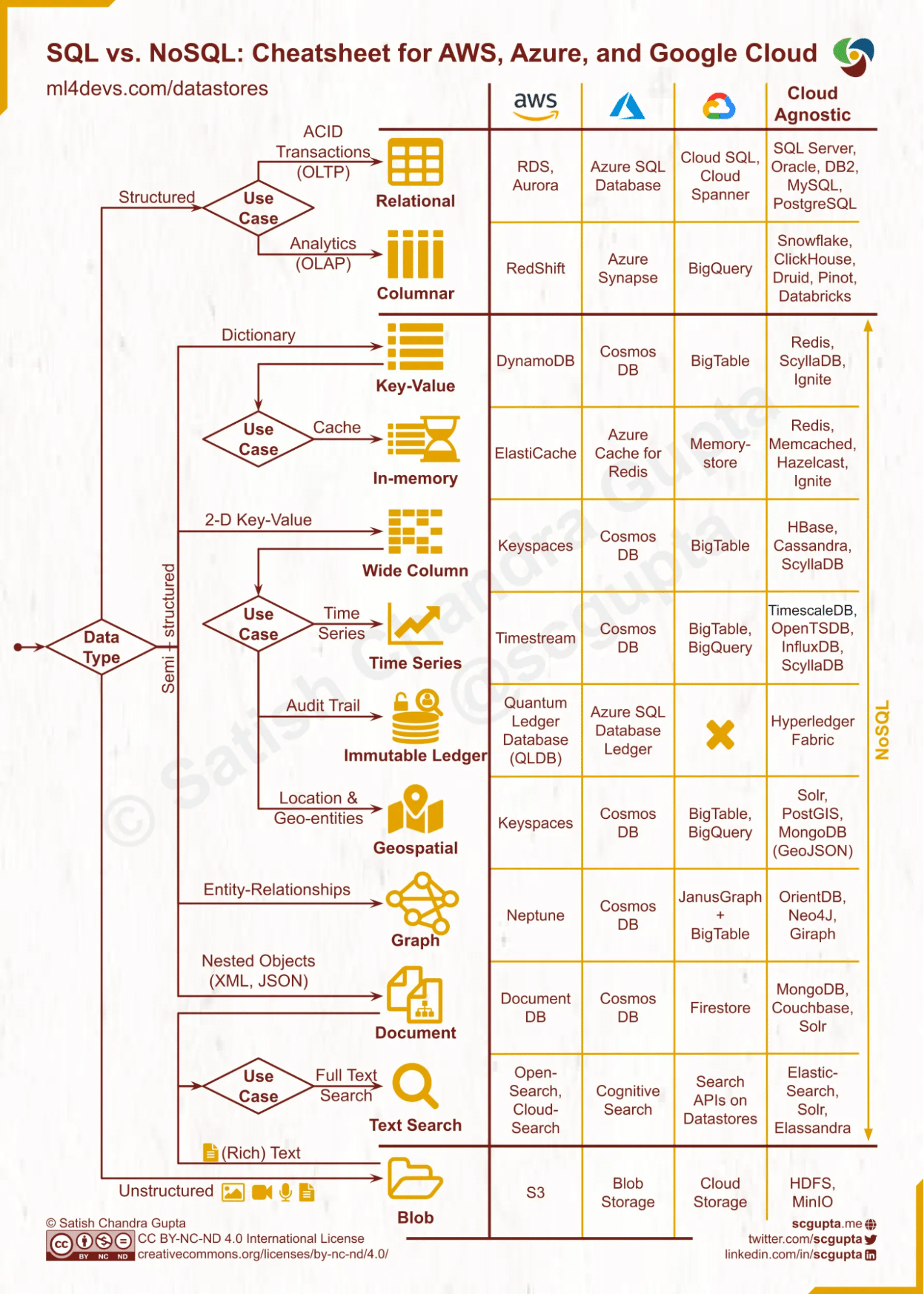
Source: This image from the ML4Devs blog illustrates the wide variety of cloud databases that can be considered.
Inputs required for architectural decision making
When developing a cloud-deployed application database, it’s crucial to take into account various factors like functionality and resiliency. Nevertheless, it’s imperative not to overlook the factor of cost. The consideration of cost-effectiveness in architecture applies to both entirely new design projects and initiatives involving the migration of an application from on-premises infrastructure to the cloud, or the redesign and refactoring of an existing application. These inputs encompass a range of factors, including organizational and technical application requirements.
When you start planning for a database implementation you want to look at the application approach and requirements to choose the right kind of database and architect it for efficiency. Considerations include the type of data that needs to be stored, how frequently is data viewed or modified, how many users will the application need to support, and how are users geographically distributed.
Additional application requirements to consider include response times, synchronous vs asynchronous patterns, connection time-to-live (TTL), encryption, administration, monitoring metrics, integration, application deployment and operations (e.g., devops).
The below table lists multiple considerations and inputs that you should reflect on, before deciding to design a database on public cloud
| Consideration | Questions to ask | Potential Decision |
| Organization core competency | Do we have or plan to hire, train, and retain staff with the required expertise? How much experience does our team have with cloud-native databases? Does our technical team have more experience with one database type or brand vs. another? Is training readily available and are team members willing to gain new skill sets? | Consider a fully-managed database service if the organization lacks the database administrators (DBAs), Business Analysts, or DataOps technical team to migrate to and use a low-cost self-managed database option. |
| Existing applications and databases | Do we have a lot of proprietary and legacy databases? Do we have legacy applications utilizing a particular database brand?
When migrating on-premises applications to the cloud, is a database migration to another approach or brand feasible? |
Consider moving to more commodity databases (with a strong community and large technical workforce available in the market). To reduce risk during migration to the cloud, consider migrating or rearchitecting the databases in a separate phase. |
| Database software installation, deployment, and operations staff | Is there a central IT team who can install the needed database(s) in compliance with the organization’s security policies and standards? How much time is spent on manual database management (create, monitor, upgrade, backup)? Do we have staff available to manually perform database management tasks? | An organization may have database installation and deployment automation to ensure that new databases can be efficiently secured and managed. There may be an internal chargeback for this capability. Automate as much as possible. Fully-managed cloud databases are more expensive, but may be a good choice if limited staff are available to perform the tasks. |
| Desire for consistency across the organization | Are there enterprise license and support contract considerations? What is the marginal cost of one additional application using a particular database brand? Do we have an internal community of expertise around a particular database type or brand? How easily can we implement and test general, “non-functional” capabilities? | The license cost of the new database brand and approach may be justified for a marginal application. Flexibility in staff assignments and database consistency could be valuable.
Consider non-functional capabilities such as high availability (HA)/disaster recovery (DR), performance, maintainability, reliability, scalability, and availability. |
| On-going database software patching | How are database software updates deployed?
Is the application sensitive to any downtime required to install high-priority patches? |
If a database software exploit is discovered and a patch becomes available, it may be essential to apply the update quickly to prevent data loss or exfiltration. |
| Operational costs | Are there cost risks with a lift-and-shift approach? Does our organization have a sizable workforce with deep technical expertise that can be allocated towards ongoing monitoring, management and operations? | Operational troubleshooting tasks may require additional visibility and could require purpose-built observability tooling. |
| Support | Does the application or vendor support other database options? | If the application requirements change, could a less expensive alternative be used? |
| Deployment time | What is the timeline to deploy the database to support your application? | Planning for the databases, planning for indexes, etc. to create a database on-the-fly vs. building tables into existing databases. |
| Application lifespan | What are the expectations of lower non-recurring engineering (NRE) vs on-going costs? | If the database is just being used to support a quality assurance (QA) test for a month vs. to support an on-going application, the database operational costs may not be a significant driver of the architecture or efficiency. |
| Licensing | Do you have on-premises licenses you can bring as BYOL to the cloud or can you add them to your Enterprise End User License Agreement (EULA) to avoid issues with license audits, container licensing, CSP PaaS license-included?
Do you have an enterprise license and you can BYOL? |
If an organization already has a database license or internal capabilities to support a particular RDBMS, there may be a way to disincentivize other database platforms.
If you are paying for a certain number of licenses that you can’t go over without ratcheting up the number of licenses you are perpetually paying for during the next 5 years of your enterprise license agreement (ELA). |
| Forecast application/database usage growth | How quickly can your DataOps team scale the database and how quickly will costs rise as usage grows? | Horizontally scalable databases may be designed to “scale out” by dynamically adding and removing additional compute and storage capacity, but may be more complex to manage. Vertically scalable databases may be easier to deploy quickly, but may be less flexible when scaling. |
| Performance | What are the service level agreements (SLAs)? | A consumer credit organization may have a 200ms SLA to deliver employment verification and credit reports. |
| ROI | Can you measure the value of the database? Do you have visibility into unit costs and unit economics? | Shared database architectures may be more efficient, but could be more difficult to attribute costs to the individual applications, users, projects, or teams. |
| Database “native feature” | Are there any features inherent or built into the database itself required for building the application(s)? | A development team may choose to use capabilities “outside” of the database as the business logic, which would allow the database layer to be replaced/upgraded more simply. |
| Documented compliance | Does the application require a security or compliance certification e.g., SOC2, HIPAA, HITRUST? | Opt for a compliant database solution on the cloud (e.g., HIPAA compliant AWS DynamoDB, RDS) |
| High availability (HA) and disaster recovery (DR) | Are there any service level agreements (SLAs) around application availability?
In the event of an outage, how quickly do we need to recover the database? |
Mission-critical applications may require higher availability than less critical applications. For example, a hospital emergency room application, executive dashboard, end-of-period financial analysis, and a daily batch record update may have very different availability requirements and costs. |
Architecture decisions required to achieve cost efficiency
When choosing a cloud database architecture, there are a number of key decisions to consider that will directly affect the cost to build, deploy, and operate the application throughout its lifecycle. Each type of database has its unique strengths and weaknesses, and the choice of a particular database type depends on the specific requirements and characteristics of the application or system being developed, the breadth of use cases, as well as critical scenarios.
Cloud service providers offer extensive guidance on which database types and deployment models are applicable to a particular scenario. Some helpful links are shared here:
- AWS: Choosing the Right Database and decision guide
- Azure: Types of Databases on Azure and database examples
- Google Cloud: Google Cloud Databases and blog post
Database deployment model
IaaS Databases and Databases-as-a-service
In an IaaS model, you (the customer/client) run your database on the cloud on a compute instance e.g., on Amazon EC2 (Elastic Compute Cloud), Google Compute Engine and Microsoft Azure Virtual Machines (similar to how you would on an on-premise data center), and retain complete administrative and operational control of the database. The need for complete administrative or operational control can be due to customizations or regulatory constraints that are required. You (the customer/client), are responsible for installing, configuring, and maintaining the database software.
In a Database-as-a-service model, you can consume a fully-managed database either directly from the cloud provider (PaaS databases such as RDS from AWS, Cloud SQL from GCP, and Managed SQL instances from Azure) or from a 3rd party SaaS vendor (from a cloud marketplace). In this model in which the cloud provider or a 3rd party provides a fully-managed and supported managed database offering, retaining most of the administrative and operational tasks pertaining to maintaining the database.
The below table should help you understand where the responsibilities for specific tasks lie:
| Feature | Responsibilities in IaaS model | Responsibility in PaaS model |
| Database optimization | Customer | Customer |
| Scaling | Customer, custom configuration | Policy-based and automated |
| HA and redundancy | Customer, custom configuration | Feature provided by cloud provider, configured by customer |
| Monitoring – Technical | Customer, custom configuration | Provided by cloud provider |
| Monitoring – Cost | Customer, custom configuration | Limited functionality provided by cloud provider |
| Backups | Customer, custom configuration | Feature provided by cloud provider, configured by customer |
| Database Patching and Security | Customer, custom configuration | Provided and dictated by cloud provider |
| Database installation | Customer, custom configuration | Provided by cloud provider |
| OS installation, patching and security | Customer, custom configuration | Provided by cloud provider |
| Hardware and physical server | Provided by cloud provider | Provided by cloud provider |
| Underlying infrastructure (power, network, cooling) | Provided by cloud provider | Provided by cloud provider |
Typically, CSP PaaS instances cost more than the corresponding IaaS instances, even when one separates out the implied license costs. However, the capabilities provided by PaaS approaches could save labor hours, generally system database administrators (DBAs). In addition PaaS approaches force certain issues, such as patching as per a schedule, which might improve compliance and security posture. It is recommended that each organization evaluating PaaS vs IaaS carefully consider all costs and benefits of each approach that they will incur or realize when making a decision. Customers should evaluate the items listed in the table as “provided by cloud provider” to determine whether the capability provided by the PaaS service is sufficient for their needs. To the extent that additional capability is needed, that can influence the decision whether or not to utilize a PaaS service vs a regular IaaS implementation
From experience, it has been observed that IaaS databases on the cloud are typically popular in environments where application requirements are strict, requiring granular control and lifecycle management and conformance to specific regulatory requirements (examples include large database deployments in banks, financial institutions etc.). PaaS databases are popular in modern greenfield web-scale architectures and deployments, where applications are dynamic and can withstand frequent changes and updates to database versions.
Another decision that organizations face could be whether to standardize on PaaS for all of their applications or consider PaaS vs IaaS on an application by application basis. This decision will most likely hinge on organizational considerations more than technical considerations.
Licensing model
Migrating existing, on-premises database licenses to cloud databases requires careful evaluation. Different licensing models may result in unexpected costs or limitations. Understanding license implications is crucial to ensure compliance and avoid penalties. For example, hybrid licensing benefits can significantly reduce the costs of running your database workloads in the cloud. Here are some key considerations:
- Commercial vs open-source databases – this is dependent on application or organizational requirements
- Bring-Your-Own-License (BYOL), e.g., under an existing End-User-Licensing-Agreement (EULA) contract vs procuring a license via the cloud service provider
- Assess how the current licensing agreement aligns with the cloud database solution
- Determine if any modifications or additional licenses are required for compatibility
- Consider potential performance tuning needs specific to the cloud environment
- Implement access control measures to manage user permissions effectively
- Regularly review license allocation and usage patterns to optimize license utilization
- Leverage observability tools to analyze your database usage patterns and spot overprovisioned and underutilized databases
- Performance tuning can help increase license utilization by optimizing frequent or long-running queries and tuning indexes
BYOL vs CSP license
When considering whether to use BYOL vs CSP vs. Marketplace purchased database licenses, consider several aspects of your expected use for each workload you are considering:
- What is the total cost of the license and support fees for each alternative? Understand the unit cost of licenses available to you internally
- Do you have access to available licenses for use?
- Will you use the instance 24×7 or more sporadically? Sometimes CSP provided licenses, which include support, are more costly than per instance EULA licenses when the instances runs 24×7 (8760 hours in a year), however if the instance is expected to run for fewer hours (say, “extended business hours” or 2880 hours – 12 hours/day during business days), CSP provided licenses might be lower cost.
- Will you use the database instance for an extended period of time? If you will only be running a database as part of a test environment, or trial, or innovation experiment, adding a license to an enterprise agreement might require your organization to pay maintenance costs for it over the life of the agreement, far beyond when you need it. So even a more expensive license purchased from the cloud provider may offer an overall lower cost over the life of the database.
Organizations are encouraged to make their own detailed calculations based on the specifics of their situation, as the cost of individual instances and your cost of licenses in a BYOL model will vary. This is an excellent opportunity to engage with your organization’s ITAM, SAM, or Procurement team to understand your database (and other) license costs and availability.
Procurement model
On the cloud, you can employ a variety of procurement strategies to secure significant savings on database spend, based on committed long-term usage. This includes reservations and commitment-based discounts. To do this effectively, you need to accurately estimate usage patterns and procure reservations for instances that run 24×7(e.g., production workloads). Non-production workloads on cloud typically run for 10-12 hrs a day and are switched on and off based on demand. Imagine 12 hrs/day, 5 days per week for non-production – a total of 240 hrs a month vs 24 hrs/day, 7 days a week for the entire month – a total of 720 hrs a month. WIth this model, you can secure a 2/3rds reduction in hours and hence costs.
This problem gets compounded especially when the cloud instances are not right-sized and you reserve overallocated instances that are under-utilized (CPU, Memory, storage). Before making commitments to savings plans or other commitment programs one should explore right-sizing the instances
Governance and engineering practices
Cloud comes with its own operating-model, fundamentally different from traditional data center-based legacy operating models.
Implementing a consistent set of best-practices for the cloud enables teams to make data-driven decisions. For example:
- Tag database instances with appropriate infrastructure and application owners
- Implement policies to identify and notify users of underside, over-provisioned
- Manage database lifecycle (e.g, storage, memory, instance type, backups)
- Choose the appropriate backup frequency and retention policy (e.g., database backups in object storage can be 80% less expensive than in managed cloud databases)
- Right-size databases by continuously monitoring usage, performance and adjusting database sizes as necessary
- Select the most cost effective database storage (e.g., standard performance SSD vs IO-intensive SSD)
- Ensure automatic snapshot deletion on retention period and lifecycle
- When you are architecting a database on the cloud, choose to optimize for memory, performance, or I/O depending on the application requirement. RDS pricing varies based on the database engine you choose.
- Explore serverless strategy for dev-test environments (so that there is no database infrastructure when the application is not running)
- Single AZ vs multi-AZ database deployment – only choose multi-AZ deployment for workloads that align with business needs for Recovery Time Objectives (RTO)/Recovery Point Objectives (RPO). Transferring data out of an AZ, and putting it in an additional target AZ – both have cost implications. Disable Multi-AZ configuration in non-Prod otherwise required.
Storage type
The cost of cloud database storage can vary based on several factors, including the cloud provider, the database engine used, the storage type, and the region where the data is stored. Relational databases typically require low-latency cloud storage e.g., block storage. Object storage is typically less performant and used to archive and back up relational databases.
Additionally, cloud providers often offer different pricing models and pricing tiers based on usage levels.
- Object Storage (Amazon S3, Google Cloud Storage, Azure Blob Storage): The most cost-effective option for storing large volumes of unstructured data. E.g., for files, backups, logs, and is ideal for scenarios where data retrieval time is not critical
- Cold Storage (Amazon S3 Glacier, Google Cloud Storage Coldline, Azure Archive Storage): Designed for long-term data archival and more cost-effective than standard object storage. However, it has longer retrieval times compared to regular object storage, making it suitable for data that is rarely accessed but needs to be retained for compliance or regulatory reasons
- Relational Database Storage (Amazon RDS, Google Cloud SQL, Azure SQL Database): Typically SSD or HDD based storage, this is more expensive than object storage, but is more performant.
- NoSQL Database Storage (Amazon DynamoDB, Google Cloud Firestore, Azure Cosmos DB): NoSQL databases generally have higher storage costs compared to relational databases.
- In-Memory Database Storage: In-memory databases, which primarily store data in RAM for faster access, can be more expensive due to the higher cost of memory compared to disk storage.
Backup
The backup strategy for databases on the cloud is somewhat different from a traditional database backup strategy in an on-premises setup. Each architectural decision has cost implications. For example,
- Is a local backup sufficient, or is replication to another Zone or Region required?
- How frequently should I backup my data based on Recovery Time Objectives (RTO)/Recovery Point Objectives (RPO)?
- What should be the retention policy for backup (based on RTO/RPO)?
- Where should I retain my backup data? An EBS volume, or an S3 bucket or archival storage?
- Can I leverage deduplication and compression to reduce backup size and storage?
- Can I leverage cloud-native tools and automation to use alternate backup strategies better suited to the cloud (e.g., point-in-time-snapshots)
Serverless Databases
A serverless database (e.g., AWS Aurora) provides the user with the underlying storage capacity for the database but without the need to provision the required compute resources to potentially avoid costs of dedicated resources. Queries to such databases are similar to making AWS Lambda calls. Also, for such databases, the approach to backups and resiliency are different from conventional databases (refer to a sample from AWS Aurora overview). As such, architecting serverless databases should be approached differently keeping these considerations in mind. While these new generation of serverless databases can be very cost effective, they should be carefully evaluated keeping in mind concurrency and security requirements of the users as not all database engines are candidates for moving to serverless.
Disaster-recovery
Database replication is the process of creating and maintaining multiple copies of a database in different locations to ensure data availability, fault tolerance, data redundancy and improved performance. Each database replication strategy associated with a disaster-recovery scenario comes with its own cost impact, including possible license cost impact resulting from the requirement to upgrade to a more capable version of the DBMS (i.e. SQL Server Standard vs Enterprise Edition). Typical replication strategies include multi-AZ and multi-region, with Primary-Secondary or active-active configurations.
It is important to choose the appropriate replication strategy based on your specific use case, workload requirements, RTO/RPO requirements, and the level of data consistency and availability needed for your application. Additionally, consider factors such as network latency, data volume, application recovery and the potential for conflicts between replicated nodes when implementing a database replication strategy. DR testing should include end-to-end from the application to the database and everything in between. Cross-region egress costs should also be estimated for various scenarios (e.g., Amazon RDS, Azure SQL, Google Cloud SQL).
Auto-scaling model
Vertical scaling involves a scale-up approach, by running the database on a larger and more performant instance. Although vertical scaling is typically simpler, it may require the database to restart, temporarily go offline, or operate in a limited capacity (e.g., read-only) while the database VM is restarted to expand storage, memory, and/or processing capacity.
Horizontal scaling involves a scale-out approach, adding more instances of the same instance type to distribute the workload across multiple servers. This option provides several advantages such as higher levels of concurrency and parallel processing without downtime, reduced latency and improved speed, elasticity – ensuring optimal performance during peak times while minimizing costs during low-demand and improved query performance.
Vertical vs horizontal scaling configuration depends on the type of database and the type of application. Not all database types support horizontal or vertical scaling.
Forecasting
Forecasting cloud database resource usage is crucial to deliver predictable business value, especially in the context of the pay-as-you-go model in the cloud. An accurate forecast of the cloud database usage means you can devise appropriate cost-savings strategies (procuring reservations and commitments, shutting down instances when not in use). However, forecasting is one of the most difficult things to do and requires a deep understanding of usage patterns and extensive coordination between engineering teams and the business. Therefore, you should leverage “well-architected frameworks” to maximize cost efficiency (AWS, Azure, Google Cloud, Oracle Cloud). Depending on the organization and how rate optimization is managed, this may require a number of steps. The following questions should be considered:
- Can the selected database engine be deployed both on-premises and in a variety of CSP environments?
- Is the database accessible from a wide variety of devices, services, and geographical locations?
- Can the database be configured for performance and scaled up/down based on application consumption requirements?
- Does the database support a wide variety of user roles and applications or is it architected for a single application?
- Does the cloud database resource and license forecast account for application usage growth?
Persona involvement
Cost-efficient cloud database architecture requires innovative leadership and collaboration among highly skilled teams. Business requirements inform the database schema as well as other architectural and design decisions such as indexing, caching, replication, maintenance, disaster recovery, among others. In the requirements phase, product, finance, procurement, and FinOps teams collaborate to define key criteria to measure the database effectiveness such as query response times for queries (e.g., inserts, updates, and deletes), database downtime for maintenance, security patches, and product updates, as well as regional availability and failover service level agreements (SLAs).
Once business requirements are well understood additional teams help define the database architecture. Database administrators (DBAs), cloud architects, functional architects, developers, cloud engineers / Ops, and DataOps evaluate the set of potential database options that will most efficiently and cost-effectively address the business requirements. Below is a sample product development timeline showing the people involved at each stage. Smaller organizations may combine these roles/responsibilities.
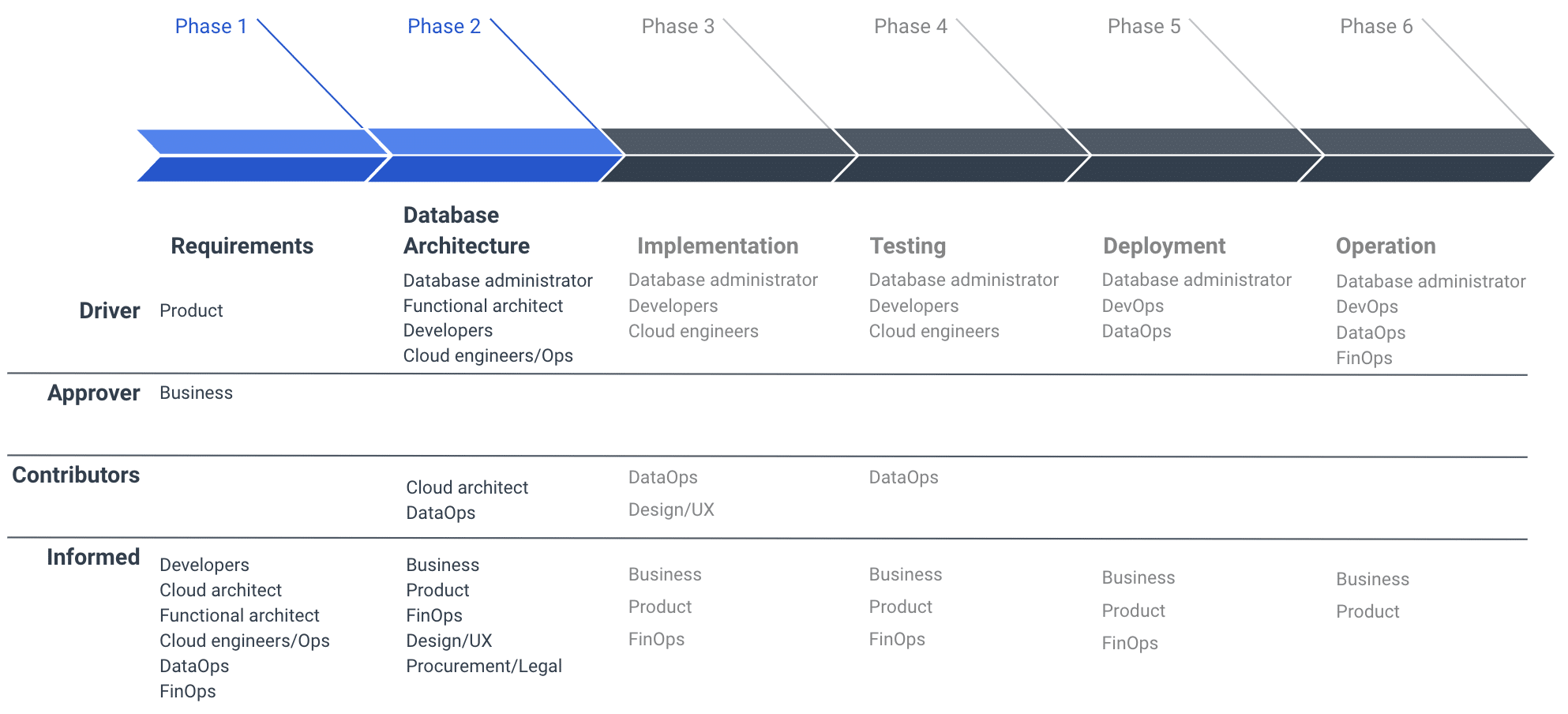
Team members involved at each phase of the cloud database lifecycle (click to see original image).
FinOps involvement should start in the requirements phase, when product and business teams start architecting a cloud database to enable new products, use cases, and features. Discussions during the architecture phase enables FinOps practitioners to more accurately estimate total cloud database costs, identify the primary cost drivers, and recommend the best strategies to maximize profitability.
Requirements phase roles and deliverables
| Team or role | Inputs to FinOps practitioner | FinOps deliverables |
| Product | Application vision, use cases, goals, business metrics, SLAs, and expected usage patterns | Cost allocation plan and examples of success |
| Finance | Overall application budget, revenue, profitability goals | Estimated annual product revenue and expenses |
| Business leader | Approves business application requirements, budget, revenue, and profitability goals | Estimated annual cloud application costs, cost drivers and break-even analysis |
| Procurement/Legal | Preferred cloud and software vendor selection criteria, spend commitments, consumption discounts, data sovereignty and regulatory requirements | Estimated annual cloud application costs |
| Cloud architect | Viability, cloud considerations | Estimated annual cloud application costs, allocation plan |
Database architecture phase roles and deliverables
| Team or role | Inputs to FinOps | FinOps deliverables |
| Product | User personas, expectations, stories, and customer feedback | Cloud application cost drivers and break-even analysis |
| Finance | Application usage growth forecasts and efficiency metrics such as cost per user, per transaction, or per session | Cloud application cost drivers, allocation plan, and efficiency metric estimates and targets |
| Business leader | Approves application development | Estimated application profit margins, efficiency targets |
| Procurement/Legal | Software-as-a-service (SaaS), Commercial off-the-shelf (COTS) recommendations for application, database, observability, and software and when to buy an application rather than build a new application | Estimated usage of committed cloud services, SaaS, and COTS software by time period and season (e.g., per hour, day, week, month, quarter, year) |
| Database administrator (DBA) | Cloud database architecture options and considerations, database schema, security, storage, caching, and monitoring | Estimated cost savings for various architectural alternatives, cloud database cost efficiency recommendations, cloud data management cost considerations |
| Cloud architect | Cloud database design options, recommendations, and considerations | Estimated cost savings with cloud database and data storage cost efficiency recommendations, cloud cost management considerations |
| Functional architect | Database hardware, software, compute, storage, and networking for functional requirements, regulatory compliance, and cost efficiency | Potential cost savings with cloud database and data storage cost efficiency recommendations and examples of success |
| Developer | Database reliability, performance, scale, resiliency goals and proof-of-concept test to establish baseline and peak usage costs | Cloud database pricing, cost benchmarks, considerations, and examples of success |
| Cloud engineer / Ops | Database reliability, performance, scale, resiliency requirements and observability plan to optimize application cost efficiency | Cloud database cost drivers, efficiency metric estimates, cost benchmarks, considerations, and examples of success |
| DataOps | Data observability plan to optimize cost efficiency for relational databases, and data pipelines | Data cost drivers, efficiency metric estimates, database and data storage cost benchmarks, considerations, and examples of success |
Conclusion
This document highlights that making strategic and tactical database design/architecture decisions have a huge impact on the total cloud application life cycle cost including development, operations, and support. We encourage readers to ensure they understand what those decisions are, the criteria driving those decisions including application requirements, organizational capabilities, and the organization’s approach to cloud database deployment. Reviewing the personas of those making these decisions is also crucial to improving collaboration.
Since cloud database cost is strongly influenced by the database capabilities and deployment model, and database architectural decisions will have a lasting financial impact, align your database deployment and operational approach early in your application development cycle in order to balance speed of deployment, database performance, and cost efficiency.
Acknowledgments
We’d like to thank the following people for their time and effort in contributing to this Working Group and to this asset.

Clinton Ford
Unravel Data
Eric Hilman
Commonwealth of Massachusetts
Jay Mohapatra
Alix Partners
Assaf Flatto
2bcloud
Sangeetha Bhosale
KPMG
Jesse Albright
Deloitte
Dr. Maneesha Asundi
Mr. Cooper
Lucas Paratore
CloudHealthWe’d also like to thank our supporters: Amit Doshi, Marcin Kaczmarek, Sonia Martínez, and Vinay Mani.
Last updated: May 27, 2025